Dans le cadre de leur quête du graal data-centric, les entreprises mettent en œuvre des plateformes Analytics et IA facilitant l’accès des métiers non seulement aux données de l’entreprise mais aussi aux données externes (Open data et Open API) afin d’alimenter différentes solutions et applications nécessaires à leur activité.
La mise en œuvre de ces plateformes transverses est guidée par une multitude de principes et d’approches architecturales. Après trois décennies de bons et loyaux services, les data warehouse se sont retrouvés face à d’autres alternatives technologiques que sont les data lake (apparus avec l’émergence du Big Data) et les data hub. Au-delà des questions de nouveauté ou d’obsolescence, c’est sur l’utilisation des données au sein de l’entreprise que doit se porter l’attention afin d’opérer les meilleurs choix technologiques et architecturaux.
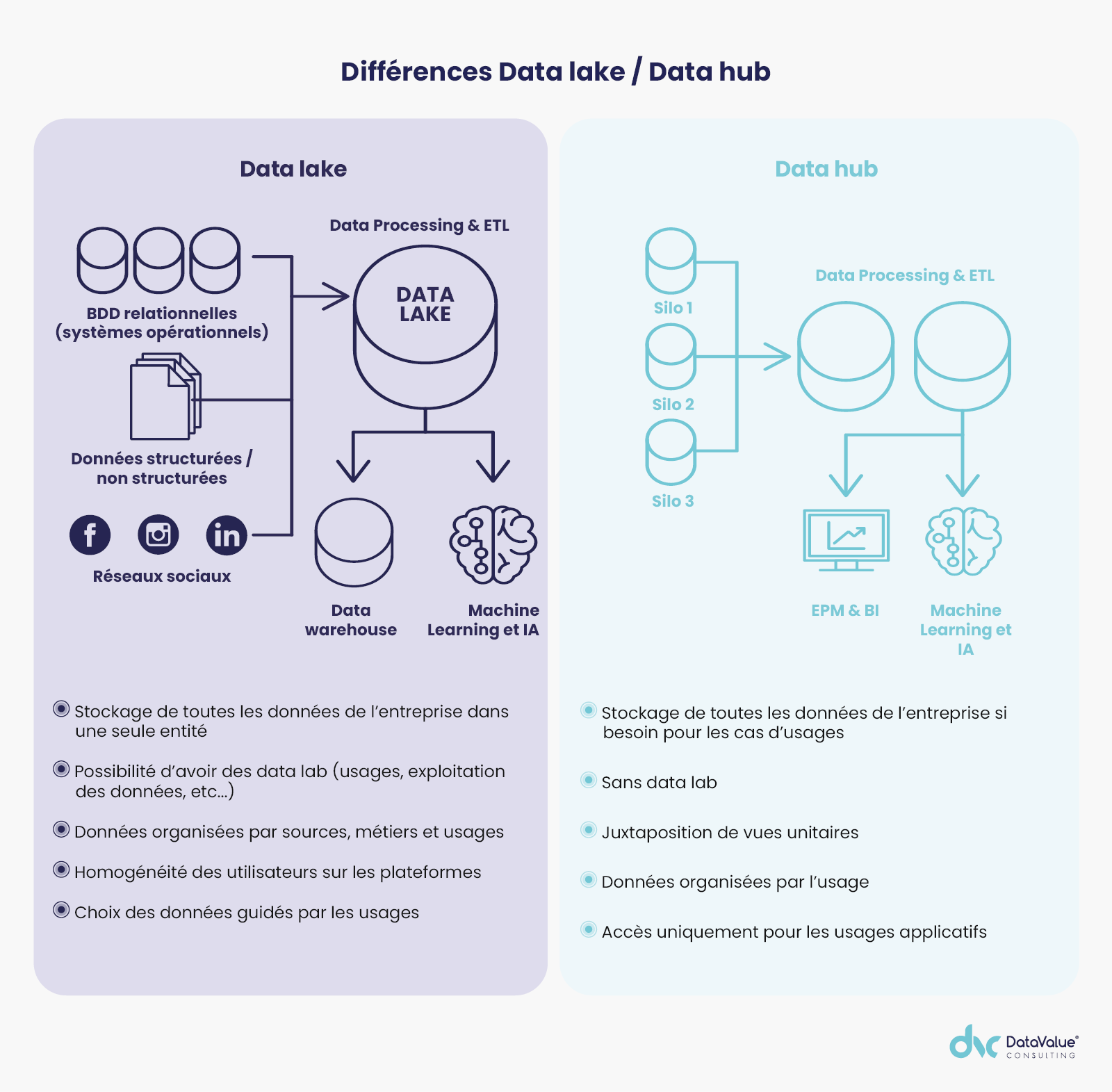
Afin de vous apporter quelques pistes de réflexion, voici les grandes différences entre les data warehouse, les data lake et les data hub.

Data warehouse : un doyen toujours d’actualité
Ce dispositif de stockage est le plus ancien des trois, avec déjà trois décennies de service à son actif. Le data warehouse (« entrepôt de données » ) est une base de données relationnelle qui stocke des données historiques et structurées. Elle est séparée des systèmes opérationnels, souvent transactionnels et voués à enregistrer une activité tels que les ERP : RH, production, vente, logistique, distribution…
Les data warehouse ont vocation à monitorer, gérer et améliorer les performances d’une entreprise. L’usage des entrepôts de données est défini lors de la conception ou de l’alimentation.
Orientés cas d’usage, ils sont utilisés directement par les dirigeants ou les managers à but de recherche et d’analyse : produire des reportings, gérer des budgets, établir des prévisions, des simulations, gérer les relations client. Le datawarehouse peut être subdivisé en datamart pour les besoins spécifiques de chaque métier : marketing, commerce, finance, RH…
Des usages spécifiques sont donc définis et la structure ainsi que l’alimentation en données du data warehouse seront cadrées en ce sens. On parle d’approche « schema-on-write». Exploitées la plupart du temps par des technologies de type SQL ou OLAP, les données doivent être préparées au format attendu pour chaque cas d’usage ou application. C’est le rôle du module ETL (Extract, Transform, Load) qui modélisera, normalisera les données en provenance de l’ERP ou d’autres sources de données. Ce module prendra également en charge l’actualisation des données puisqu’elles sont généralement statiques, sans mise à jour, au sein d’un data warehouse.
A noter que le temps de mise en place d’un data warehouse peut s’avérer assez conséquent, de plusieurs mois jusqu’à parfois plusieurs années.
Data Lake : Think Big Data
Les data lake sont des espaces de stockage aux capacités a priori idéales.
Apparus vers 2010 peu avant l’arrivée du Big Data, ils sont en mesure de stocker rapidement (pas de modélisation préalable) des données brutes, qu’elles soient structurées, semi-structurées ou non structurées et ce sans hiérarchie ni organisation.
Les technologies de clusters et framework de fichiers distribués de type HDFS permettent de gérer des volumétries de données considérables tout en offrant un espace de stockage unique, centralisant toutes les données de l’entreprise.
De plus, la motorisation des data lake par des technologies open source offrent un coût d’exploitation intéressant, en regard de data warehouses fonctionnant avec des logiciels sous licence éditeurs. La qualité prédominante des data lake est donc la flexibilité.
Ils ne gèrent cependant pas les technologies SQL, très usitées par exemple dans les data warehouse.
La data est utilisée davantage par les data scientists et peut s’avérer inaccessible aux utilisateurs métier. C’est une différence d’importance avec un data warehouse qui est structuré directement à partir d’un besoin. Les données d’un data lake sont stockées pour leur part jusqu’à l’émergence du besoin des utilisateurs, besoin qui définira leur modélisation. C’est donc une approche inverse, appelée « schema-on-read », où le potentiel des données est estimé après leur collecte. C’est tout l’art des data scientists et du data mining que de trouver des corrélations ou définir des applications à partir de cette masse de données non structurée.
Volume, quantité de données… Tout ceci doit cependant être bien ordonné et entretenu. Ce n’est pas parce qu’un data lake héberge des données non-structurées que lui-même ne doit pas l’être.
Une bonne gouvernance des données sera indispensable, sans quoi le data lake virera au data swamp (marécage de données) et perdra sa valeur.
Enfin, en tant que point central et unique de stockage des données pour toute l’organisation, la vigilance en matière de sécurité et de confidentialité devra être accrue.
Le Data Hub : le meilleur des deux mondes ?
Le data hub ou hub de données est un répertoire central et unifié qui connecte les différents systèmes : ERP, CRM, BI, EPM, applications web, SaaS… En dématérialisant ces silos, il coordonne les connexions et les flux de données entre chacun des systèmes grâce à une centralisation physique ou virtuelle des données. Il maximise l’utilisation des données pour différents profils d’utilisateurs.
Le data lake et le data hub se partagent des objectifs communs, tels que l’analyse Big Data, la rationalisation de la gestion de la donnée ou l’optimisation des accès à cette dernière tout en favorisant les nouveaux usages.
Cependant, les deux architectures présentent des différences sur plusieurs aspects.
Ainsi, malgré la notoriété des concepts « Big Data » ou « data lake », 80 % des clients de solutions de stockage en France ont adopté une architecture data hub avec des espaces orientés métier/usages servant les cas d’usage, c’est notamment le cas de Faurecia. Le data lake conserve pour sa part une connotation de réceptacle de données, moins orienté use case comme nous l’avons évoqué précédemment.
Pour faciliter l’émergence de nouveaux projets métiers et data, le data hub est plus approprié de par sa souplesse dans l’ajout de cas d’usage métier, contrairement au data lake qui implique une dépendance envers les propriétaires de la donnée.
Le data hub va harmoniser toutes les données qu’il ingère des différents silos puis, grâce à une stratégie d’indexation sur les données, offrira des requêtes et des analyses plus rapides. Ceci concerne des données structurées ou semi-structurées.
Il apporte une facilité d’utilisation : à l’instar d’un data warehouse, il n’est pas nécessaire de disposer d’une connaissance parfaite de son SI ni des données utilisées dans les cas d’usage alors que ces éléments constituent justement des prérequis indispensables pour le recours à un data lake.
Il n’est pas non plus nécessaire de disposer d’un modèle de données unique dans un data hub. Il est possible d’y lire et écrire des données depuis n’importe quelle application alors qu’il n’est possible de le faire que depuis l’application source d’un data lake ou d’un data warehouse.
Enfin, concernant l’hébergement, le data lake sera quasiment systématiquement hébergé sur une plateforme Hadoop, ce qui ne sera pas obligatoire avec un data hub.
La rédaction vous conseille
> Points de vigilance pour réussir sa migration Big Data
> Quels coûts directs et indirects pour votre migration Big Data ?
