Secteur porteur en plein développement depuis plusieurs années, le Big Data offre une multitude d’usages et de promesses. Il fait face à une augmentation exponentielle de son usage, de la complexité et de la densité des données.
Les enjeux se portent à présent sur le traitement de toutes ces données plutôt que sur leur acquisition. Un ordinateur unique étant limité dans ce processus, de nouveaux paradigmes sont désormais mis en place pour y répondre. L’un d’entre eux est le calcul distribué.

1. Le calcul distribué : une nécessité dans la gestion du Big Data
Le calcul distribué permet de diviser un problème unique en une multitude de problèmes plus petits afin de calculer en parallèle chacun de ces problèmes. De manière standard, un ordinateur calcule de manière sérielle, une tâche après l’autre. L’idée derrière Ray est de passer du paradigme sériel au distribué.
L’objectif est de calculer les tâches en même temps sur l’ordinateur (via le multi Thread) ou via plusieurs ordinateurs (cluster). Cette approche augmente grandement la vitesse de calcul du problème de base, et permet d’obtenir du temps réel là où, auparavant, plusieurs minutes voire plusieurs heures étaient nécessaires pour obtenir le même résultat. En revanche, les possibilités qu’apporte ce type de fonctionnement présentent encore quelques limites, la tâche distribuée nécessitant parfois une réponse antérieure. Je rentrerai plus en détail lors de mon exemple d’application, mais il faut savoir que certaines limites existent encore et que l’augmentation de la vitesse du calcul n’est pas linéaire et/ou proportionnelle au nombre de machines disponibles.
2. Ray, un Framework de calcul distribué pour le Machine Learning
Optimisé pour l’intelligence artificielle
Ray est donc une structure qui se définit comme étant un Framework simple pour construire des applications distribuées et performantes. Elle est développée en Open source par UC Berkeley RISESLab et est spécialement conçue pour construire facilement des applications avancées d’IA de manière distribuée, en utilisant pour API le langage Python.
L’on parle avant toute chose d’une API simple : simple car celle-ci ne nécessite que très peu de modifications pour passer par exemple d’une application codée en Python, dite sérielle, vers une application dite distribuée. Le panel d’applications où il est possible de mettre en place Ray est vraiment large. Ce n’est pas un Framework limitant. Ainsi, l’on peut faire des applications de Machine Learning, mais aussi des applications web et du Scraping, entre autres.
L’objectif de Ray est de répondre à la complexification des modèles et des algorithmes utilisés actuellement dans l’optique d’accélérer considérablement la vitesse de calcul, tout en assurant un processus complet du développement de l’application et la gestion des flux serveurs jusqu’au front.
Pour ce faire, en addition de Ray CORE qui constitue le cœur de la solution, Ray est constitué de plusieurs librairies propriétaires :
- Ray CLUSTER permet d’utiliser Ray au travers d’un cluster de Machine.
- Ray SERVE permet de rendre l’application scalable (communication entre les serveurs de
Worker et les Driver) - Ray TUNE permet l’exécution d’hyper-paramètre à grande échelle et en parallèle.
- RLLIB permet de faire du Reinforcement Learning de manière scalable et sur une API unifiée
- Ray SGD permet d’entraîner plusieurs modèles en parallèle
À ces librairies s’ajoutent plusieurs intégrations de la communauté, du fait d’être une solution en open source, les possibilités sont ouvertes et prometteuses. À travers sa volonté d’être optimisé pour le Machine Learning, Ray permettra de rendre les modèles bien plus efficaces. Allant du choix du dit modèle de neurone, jusqu’à rendre possible des calculs en temps réel, calculs qui nécessiteraient des banques de données conséquentes.
Architecture
Les tâches de l’architecture de Ray sont planifiées et distribuées de manière ascendante : elles sont soumises de haut en bas du driver vers les workers, puis transmises au planificateur local. Celui-ci les distribuera au cluster. De plus, les tâches peuvent être transmises au planificateur global si nécessaire. Les flèches en pointillés ont un taux de demande moins important.
Worker : le Worker est celui qui va calculer les tâches soumises au travers de l’ordonnanceur. La tâche n’est lancée par le Worker que s’il dispose des ressources requises disponibles (CPU / GPU).
Le driver : c’est un Worker spécifique qui exécute le programme Python et soumet les tâches locales à l’ordonnanceur local. Régulièrement ce Worker ne calcule pas la tâche soumise afin de rester disponible.
Planificateur local : Un planificateur local est présent sur chaque nœud du cluster exploité par Ray. Sa fonction consiste à assigner des tâches aux travailleurs disponibles sur le nœud et à transmettre le cas échéant les tâches au planificateur global.
Planificateur global : Un planificateur global s’exécute sur le nœud à partir duquel Ray est exécuté. Il reçoit les tâches des planificateurs locaux et les affecte à d’autres planificateurs locaux qui ont les ressources pour exécuter cette tâche.
GCS : le « Global Control Store » maintient l’ensemble du contrôle d’état du système, il est spécifique à Ray. Il permet de maintenir une tolérance aux pannes et un faible temps de latence pour un système qui engendre de manière dynamique des millions de tâches par seconde. La tolérance aux pannes en cas de défaillance d’un nœud nécessite une solution pour maintenir les informations d’object ID. Les solutions existantes se concentrent sur le parallélisme à gros grains et peuvent donc utiliser un seul nœud, par exemple le driver, pour stocker les objects ID sans affecter les performances.
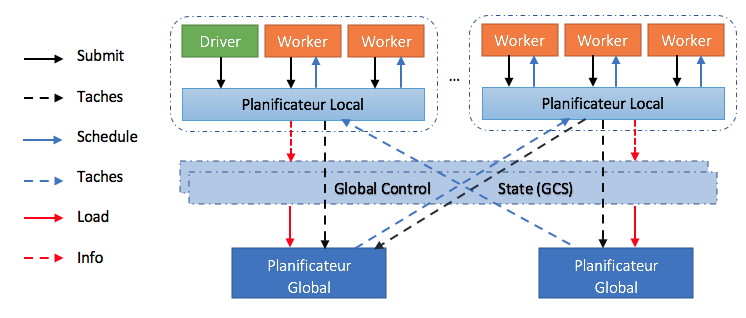
Le planificateur global tient compte de la charge et des contraintes de chaque nœud pour prendre des décisions. De manière plus précise, il identifie les ressources disponibles au sein des nœuds et détermine donc celui qui aura le temps d’attente le plus bas. Pour un nœud donné, cette durée est égale à la somme du temps estimé pendant lequel la tâche sera mise en attente sur ce nœud, et du temps estimé de transfert des entrées de la tâche (taille totale des entrées/bande d’entrée moyenne). En outre, l’ordonnanceur global calcule l’exécution moyenne des tâches et la bande passante moyenne de transfert en utilisant une moyenne exponentielle simple. Si le planificateur global devient un goulot d’étranglement, nous pouvons instancier plus de répliques partageant toutes les mêmes informations via le GCS. Cela rend l’architecture de ce planificateur hautement évolutive.
Une API simple
L’API de Ray CORE se résume de manière succincte en quatre éléments : un initialiseur import ray, ray.init(), un décorateur @ray.remote, un activateur .remote et un récupérateur .get.
La commande ray.init() initialise le cluster de Ray, l’argument redis-adress est utilisé pour donner une adresse IP et le Port sur lequel Ray se connectera. Si il n’y a en revanche pas d’argument spécifié, Ray se connectera au cluster local. Dans le cas précis d’un ordinateur hors grid, Ray fera de l’ordinateur local un cluster, permettant ainsi à Python de faire simplement du multithreading.
Après avoir importé et initialisé Ray, l’on applique ce Framework à une fonction comme suit ; le décorateur : celui-ci se dispose au-dessus de la fonction que l’on souhaite. Il permet d’exécuter la fonction Python de manière asynchrone.
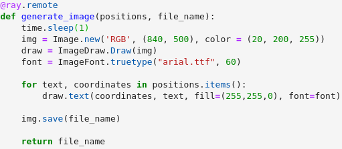
Une fois la fonction décorée, celle-ci est désormais utilisable en utilisant Ray, mais cela n’est pas automatique, ainsi pour activer Ray sur cette fonction à un moment spécifique du code, il suffit de l’appeler avec l’activateur, .remote. Cela permettra de basculer automatiquement la fonction vers Ray et donc impliquera que son calcul soit exécuté de manière distribuée.
![]()
Du fait de la parallélisation des calculs et surtout de la possible utilisation de cluster de machine, il est nécessaire de donner une ID au calcul afin de pouvoir le récupérer et d’être certains de savoir à quoi il correspond. Pour ce faire Ray lui donne immédiatement un Object réf. Il permet de garantir l’intégrité du calcul.
Cette opération se déroule comme suit : l’on demande à Ray d’exécuter une fonction ; Ray va ajouter cette tâche aux machines qui servent de Worker et nous donner l’object ID de la tâche. Une fois cela fait, il ne nous reste plus qu’a demander le résultat de la tâche en faisant appel à .get(Object_ref). Le .get est utilisé comme fonction pour convertir tous les .remote en des objets Python et ce dès que la tâche est complétée. Afin de savoir l’état des jobs en cours, en attente et finis, il suffit de faire la commande ray.wait : celle-ci listera les états d’avancement des tâches.

En revanche il faut prendre garde au moment de coder l’application car le .get est une opération bloquante. Il va stopper la boucle du code pour attendre le retour de l’élément et bloquer par conséquent les autres processus, le temps de récupérer l’élément spécifique.
3. Une Render Farm : un exemple de calcul distribué
L’exemple d’application que je vais vous proposer est celui d’une Render Farm. Le but de ce cas est d’une part de démontrer que Ray peut s’appliquer à tout type de support, mais aussi d’en montrer quelques limites. L’objectif de ce cas est de générer un GIF animé montrant le trajet d’un texte morcelé sur une image qui s’assemble en une phrase. Cette programmation est donc basée sur la position initiale, puis sur la position finale (Target). Les images intermédiaires sont calculées automatiquement par le programme et distribuées au sein de Ray en Multi Thread. Afin de démontrer cela, j’ai instauré la règle qu’à chacune des images calculées, le code se mette en attente une seconde. Cela permettra d’avoir un repère de temps pour quantifier les éléments.
Ainsi le texte animé est constitué de 3 parties : « Data », « Value » et « Consulting ». Chacune de ces parties part d’une extrémité de l’image pour aller vers son centre afin de former le sigle « Data Value Consulting ». Ceci implique 3 calculs par image.Le but est de montrer la distribution des tâches et de faire en sorte que chacun des trois calculs soit fait en simultané et non en série. Ainsi nous calculerons les coordonnées des trois éléments de la première image, puis les trois éléments de la suivante et s’en suit jusqu’à la dernière image (image n°10).
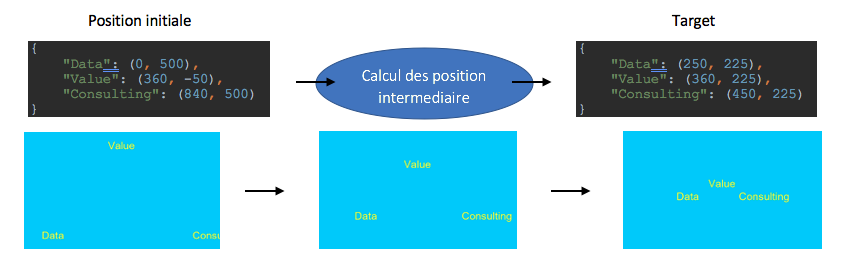
Le cas particulier de ce type de calcul implique un cache en plus du rendu des images. Vu que la suite d’images n’est pas encore calculée (l’on ne connaît que les informations de l’image 1 et de l’image 10), il sera nécessaire de calculer la position des intervalles. Ainsi pour calculer l’image n, il sera nécessaire de calculer l’image n-1, pour l’image n-1 le calculer de l’image n-2 devra être fait et cette répercussion se poursuit jusqu’à la première image. De manière imagée je compare cela à une balle qui rebondit. Imaginons que celle-ci rebondisse 3 fois : afin de savoir où elle sera lors du troisième rebond il est nécessaire de savoir où elle est lors du second, et ainsi de suite lors du premier. Cet effet de chaîne est bloquant pour le calcul distribué, car il doit être exercé quoiqu’il arrive en sériel. C’est l’une des limitations structurelles du calcul distribué.
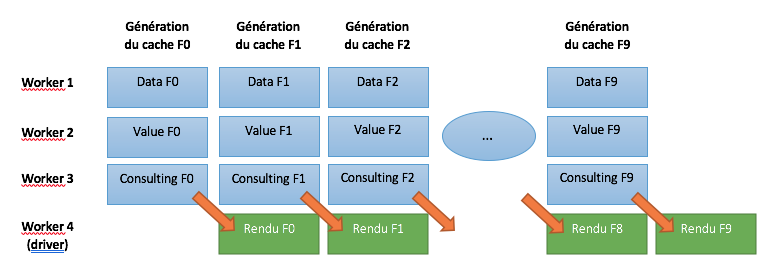
Ainsi pour optimiser au mieux une parallélisation du programme, l’idée est d’avoir un Worker par donnée à calculer sur une image et de rendre l’image de n-1 en même temps que le calcul de n. Ceci me permet dans le présent cas de passer d’un ratio de 40 unités de temps (10x(3 éléments)+10 rendus d’image) à un ratio de 11 unités de temps 10+1 rendu (10 calculs de cache distribués +10 rendus d’image -9 mis en parallèle des calculs de cache.)
4. Conclusions
Benchmark de la solution Ray
Afin de voir la différence de puissance entre un programme en Python avec ou sans Ray, nous allons étudier ce stress test. Il s’agit d’un calcul incrémental sous la forme suivante, i x j x k, pour i de 0 à l’input value, pour j de 0 à i, pour k de 0 à j, ce qui donne par exemple avec un input valu de 200 :
- [1 => 200]x[1 => 200]x[1 => 200]=> 8 000 000 d’opération unique.
Voici le résultat du Bench pour des input value de 200 / 300 / 400 : en mono thread, en multithread de 4 cœurs, et via un cluster de 3×28 cœurs.
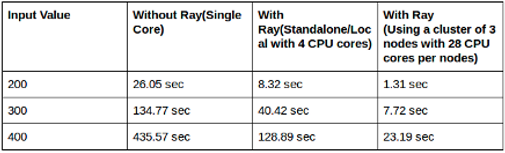
L’on remarque un facteur de ~18 avec le cluster et de ~3 avec le multi thread. Cela est une preuve de l’efficacité de Ray ouvrant de larges possibilités pour l’usage de calculs. Ceux-ci sont au travers l’architecture de Ray facilement modifiable et scalable de manière non limitée, le sujet clés à prendre en compte est de bien étudier la façon de coder afin de limiter autant que possible les opérations bloquantes comme cité ci-dessus (par exemple le .get ou encore les limitations dues aux calculs nécessitant des caches de données).
RayOnSpark
RayOnSpark est développé pour permettre aux applications distribuées développées avec Ray de s’intégrer de manière transparente dans les pipelines de traitement de données Spark. Ainsi, comme son nom l’indique, il exécute Ray au-dessus de PySpark sur des clusters de Big Data tels que Kubernetes, Mesos, Yarn.
L’architecture de RayOnSpark est modélisée comme suit : l’on crée un objet SparkContext sur le nœud du Driver et celui-ci lance plusieurs exécutants Spark à travers le cluster pour effectuer les Tasks. Ainsi, dans l’implémentation de notre RayOnSpark, nous créons un objet RayContext sur le Driver Spark et il utilise le SparkContext existant pour lancer automatiquement les processus Ray à travers le cluster.
Les processus RAY existent aux côtés des exécuteurs Spark. L’un des processus de Ray est le Master de Ray tandis que les autres sont des processus esclaves de RAY, aussi appelés Raylets. De plus, le RayContext est également responsable de la création d’un RayManager à l’intérieur de chaque exécuteur Spark pour gérer les processus Ray. C’est-à-dire que le RayManager arrêterait automatiquement les processus Ray et libérerait les ressources correspondantes une fois l’application Ray terminée.
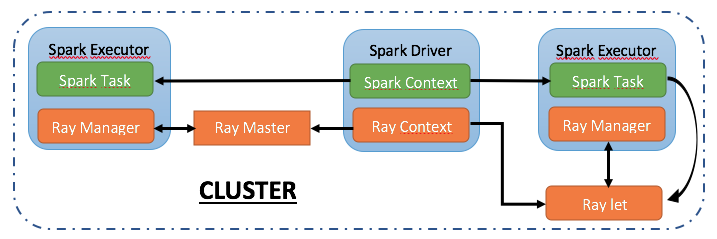
Ainsi, dans le réglage de RayOnSpark, nous avons des processus Ray et des processus Spark qui existent dans le même cluster : il est donc possible, pour un ID Spark en mémoire ou des Dataframe, d’être directement diffusé dans les applications Ray à des fins avancées pour du Machine Learning.
Concernant l’utilisation de RayOnSpark, il est nécessaire d’ajouter quelques lignes de code pour exécuter directement les applications Ray sur les clusters. Ce processus se résume en 3 étapes. Tout d’abord, vous devez importer les paquets correspondants dans notre projet et créer un objet SparkContext en utilisant l’API init_spark_on_ « nom du cluster ». Dans cette configuration, Spark aide à empaqueter et distribuer l’environnement spécifié (Ex : Conda) avec tous les chemins et dépendances à travers tous les exécuteurs Spark. Ainsi, lors de l’appel de cette fonction, l’on peut également spécifier la configuration Spark comme le nombre d’exécuteurs.
La deuxième étape est de créer l’objet RayContext. RayContext est le point de contact entre Ray et Spark. Vous pouvez entrer des configurations spécifiques (comme le stockage de mémoire objet) puis appeler RayContext.init pour lancer tous les processus Ray à travers le cluster. Après avoir réalisé ces deux étapes, nous avons donc maintenant à la fois Spark et Ray prêts dans le cluster.
La dernière étape consiste à pouvoir écrire directement le code Ray, et de faire fonctionner sur le cluster le job. Une fois l’application Ray terminée, l’on peut appeler RayContext.stop pour arrêter le cluster Ray. Voici essentiellement le code nécessaire pour utiliser RayOnSpark.
Cela rejoint la philosophie de Ray, à savoir un Framework simple pour construire des applications distribuées et performantes. Cette simplicité, étant même portée sur son intégration aux autres Farmeworks et solutions, fait de Ray – par son efficacité prouvée au travers de son Benchmark et de sa simplicité d’implémentation – une solution ayant toutes les cartes en mains pour répondre aux besoins de l’évolution et de l’exploitation du Big Data.
Sources :
Philipp Moritz, 2018 « Ray : A Distributed Framework for Emerging AI Applications » https://arxiv.org/pdf/1712.05889.pdf et https://docs.ray.io/en/latest/
Sarthak Chakravarty 2018 « Scaling Python modules using Ray Framework » https://medium.com/formcept/scaling-python-modules-using-ray-framework-e5fc5430dc3e
Kai Huang, 2020 « Running emerging AI applications on BIg Data platforms with Ray on Apache Spark « https://databricks.com/fr/session_na20/running-emerging-ai-applications-on-big-data-platforms-with-ray-on-apache-spark

Par Josselin Leclerc
Data Engineer chez DataValue Consulting
