Data Mesh : de quoi parle-t-on ?
Les données sont incontournables dans un système d’information des entreprises. Certaines entreprises exploitent les données pour créer de la valeur et pour en tirer un avantage concurrentiel.
Souvent, les données prolifèrent et la démultiplication des technologies afférentes à la gestion des données rendent la maitrise difficile de l’écosystème des données.
Une équipe centrale est-elle en capacité de conjuguer les technologies et les concepts de collecte, de traitement, de stockage et de diffusion pour toutes les données d’une entreprise ? Cette même équipe est-elle en capacité à comprendre la multitude de définitions des données métiers ? Peut-elle constituer un goulot d’étranglement technologique et métier pour l’entreprise ?
Au fil du temps et des mouvements de mise en œuvre de plateforme Data Lake, un terme revient de plus en plus dans l’actualité : le Data Mesh. Faut-il y rester indifférent ?

Data Mesh : pour quoi faire ?
Data Mesh se présente comme une nouvelle approche pour mettre progressivement sous contrôle les données de l’entreprise.
Dans bien des cas, le partage, l’accès et la recherche des données peuvent se révéler difficiles, l’architecture sous-jacente complexe à faire évoluer et une vision des besoins données sont pénibles à consolider à l’échelle de l’entreprise.
Data Mesh est une approche qui peut se révéler payante pour l’entreprise qui souhaite initier une démarche data sur un premier périmètre de données tout en limitant les impacts techniques et les investissements sur son système d’information. Cette première initiative en cas de succès peut déboucher sur une démarche de stratégie d’entreprise.
Qu’est-ce qu’un Data Mesh ?
Les principes fondateurs du Data Mesh
Le Data Mesh représente un réseau de domaines de données interconnectées.
Un domaine couvre un périmètre fonctionnel de données métiers. Chaque domaine est conçu et implémenté de manière isolée. Chaque domaine est autonome et libre dans son développement mais chaque service peut dépendre l’un de l’autre pour satisfaire les attentes des utilisateurs.
Data Mesh présente un pattern qui définit la manière dont les organisations doivent s’organiser en un ou plusieurs domaines de données avec pour but de délivrer des produits de données entreprise. Il s’appuie sur des producteurs de données et des consommateurs de données et fournit un modèle de gouvernance fédéré à travers une politique centralisée.
Le producteur de données est expert du domaine, propriétaire des données et gère la gouvernance de son domaine, gère la qualité des données et les métadonnées.
Le consommateur de données gère les priorités métiers, les développements d’analyse de données métiers, la découverte des données, le développement de pipeline des données, la création des informations.
Le Data Mesh est fondé sur 4 principes clés :
- Le propriétaire de domaine métier,
- Le produit « Data »,
- La plateforme de données en self-service,
- Une gouvernance de calcul fédérée.
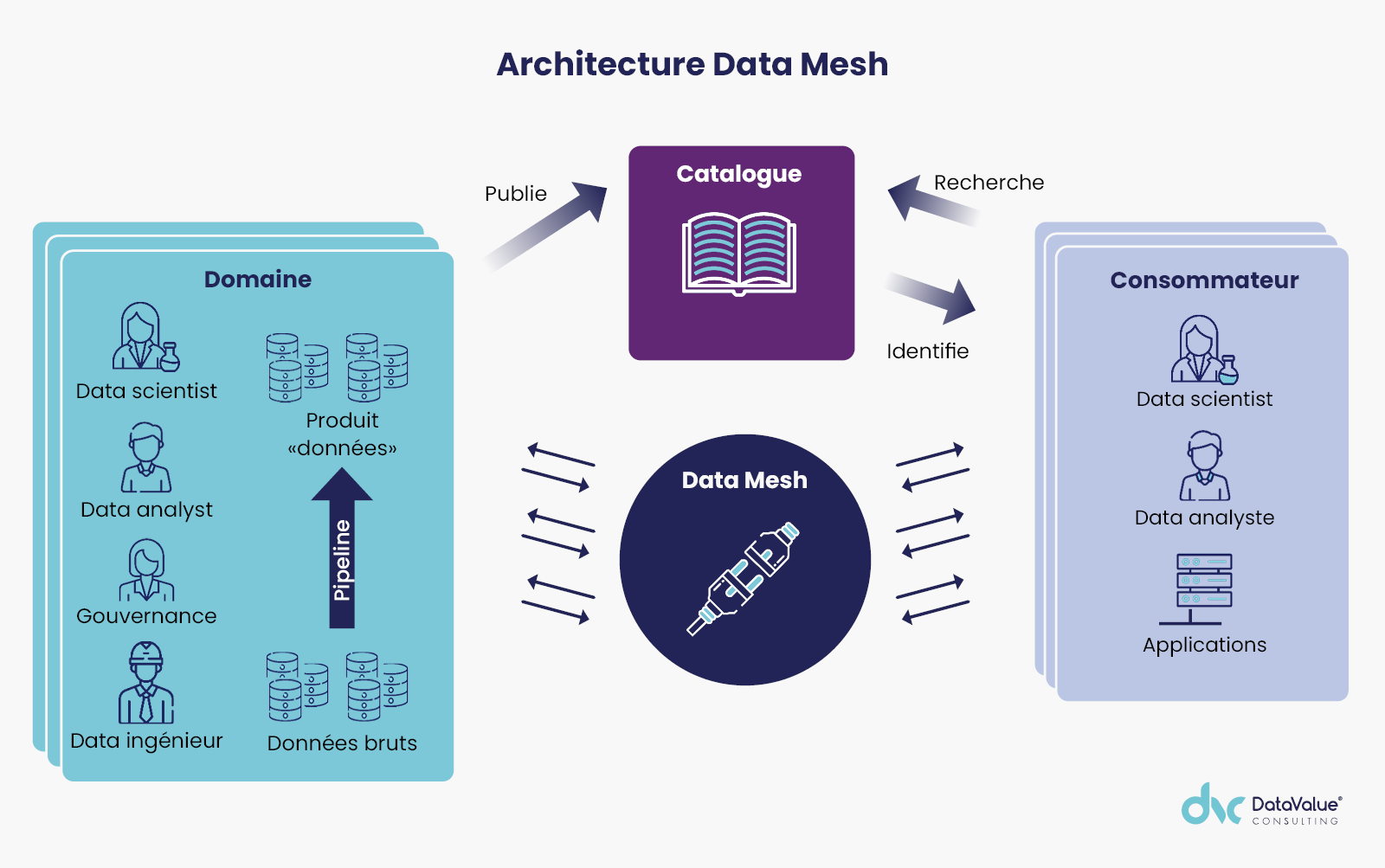
Le propriétaire de domaine métier
Les données de l’entreprise sont organisées en domaine. Un domaine représente un ensemble d’activités lié à un métier de l’entreprise. Chaque domaine s’appuie sur des données et est piloté par un responsable : le propriétaire de domaine.
Le propriétaire de domaine est responsable d’héberger et de mettre à disposition les données de son périmètre en tenant compte des besoins des consommateurs. Ses données sont exposées sous la forme de produit.
En effet, en tant qu’expert, il pilote l’ensemble des sachants de son périmètre métier pour concevoir un produit aligné avec les attentes des utilisateurs. Les données opérationnelles sont présentées de manière plus conviviale pour les consommateurs de données.
Le produit « Données »
Une donnée doit être considérée comme un produit. Cela implique de changer une vision des données souvent orientée technique. Il s’agit d’appréhender la donnée avec une vision métier tout en intégrant l’expérience des utilisateurs des données. Une donnée doit être gérée, valorisée, documentée et utilisée.
Tout produit « Donnée » doit avoir les caractéristiques suivantes pour satisfaire les besoins de l’expérience utilisateur :
- Découverte « Je peux chercher une donnée » : l’utilisateur final et les utilisateurs au sein des domaines peuvent découvrir les données avant d’accéder au produit « donnée »
- Adressable « Je peux utiliser une donnée » : la donnée doit être accessible par une interface programmable et doit être documentée ;
- Fiable « Je peux avoir confiance en la donnée » : l’utilisateur final doit comprendre le niveau de qualité des données pour être confiant dans les résultats d’une analyse ;
- Définie : la donnée doit être documentée afin d’être utilisable ;
- Auto-description « Je peux comprendre une donnée » : un utilisateur hors domaine qui construit un produit data doit avoir toutes les informations nécessaires pour utiliser la donnée ;
- Interopérable « Je peux travailler avec d’autres données produits » : par la définition de standards inter/intra domaines. Ces standards permettent de simplifier le partage, la normalisation et la terminologie des données sans sollicitation des producteurs des données ;
- Sécurité « Je peux protéger une donnée contre des accès non autorisés » : la sécurité doit être intégrée dans la conception du produit afin de maitriser l’accès aux données.
Ce packaging de caractéristiques permet de simplifier et de démocratiser l’usage des données quel que soit le niveau d’implication des utilisateurs dans les données et quelle que soit la donnée métier.
Un produit « Donnée » peut être associé à un ensemble d’informations descriptives utile, facilement accessible pour développer les usages et améliorer leur compréhension.
À titre d’exemple, on peut notamment citer comme élément descriptif :
- Un nom unique ;
- Un identifiant unique ;
- Une définition ;
- Niveau de qualité ;
- Niveau de disponibilité ;
- Règles de sécurité ;
- Modalités d’accès.
La définition d’un produit de données implique de répondre aux questions suivantes : Quelles sont les parties prenantes des données ? Quelles sont les données utilisées ? Quelles sont les sources des données ? Quelles sont les données pouvant appartenir au même domaine ?
Une plateforme en self-service
Chaque domaine s’appuie sur une plateforme technologique fournissant des capacités de gestion des données telles que l’ingestion, le traitement, la transformation et la mise à disposition des données.
Un des principes du Data Mesh est de définir une frontière entre le responsable des données et le responsable de la plateforme technologique. Le responsable de la plateforme technologique ne gère pas les données du domaine et le responsable de domaine ne gère pas la plateforme technologique. La plateforme technologique doit être agnostique au domaine, c’est-à-dire qu’elle ne doit pas être spécifique à un domaine.
Une équipe centrale IT peut avoir la responsabilité de gérer et de maintenir cette plateforme technologique pour les besoins de l’ensemble des domaines entreprise.
Une gouvernance de calcul fédérée
Une gouvernance des données peut être définie dans un intra domaine ou inter domaine. La gouvernance des données peut s’adapter en fonction des besoins de l’entreprise. Elle doit permettre de développer de la valeur et de maitriser les risques.
La question de la gouvernance des données se pose sur plusieurs processus de l’entreprise :
- Quelle sécurité sur les données ? Il faut être en capacité de définir des droits d’authentification et d’autorisation pour l’usage des données ;
- Quelles sont les données conformes ? Il faut s’assurer que les données sont alignées avec les différentes réglementations et politiques de sécurité définies ;
- Quelle est la période d’utilisation des données ? Il faut avoir la capacité de définir la plage d’utilisation des données ;
- Quelle est la confiance accordée sur les données ? Il faut avoir la capacité d’évaluer la qualité des données.
- Quel est le vocabulaire commun ? Il faut avoir la capacité d’harmoniser les termes métiers utilisés dans l’entreprise.
- Quelle est la source de référence des données ? Il faut avoir la capacité de définir les responsables de données.
Data Mesh : quelle architecture et quels avantages ?
Une architecture se compose d’une constellation de produits data interconnectées, où chaque produit dispose d’une couche de persistance et expose aux consommateurs des services de manipulation des données.
Des indicateurs d’observabilité, opérationnelle, de qualité, de rendu utilisateur complètent le produit. D’autres composants peuvent compléter cette architecture data mesh tel que : des outils de découverte et d’exploration des données, le data linéage des données, l’inventaire de l’exhaustivité des données métiers exposées, un glossaire des vocabulaires métier.
Le Data Mesh permet d’atteindre certains objectifs :
- D’ouvrir l’accès aux données au plus grand nombre tout en limitant les couts de transformation IT. Le développement en mode produit permet de s’assurer que les données sont réutilisables, interopérables, interprétables et compréhensibles simplement.
- De développer progressivement une prise de conscience de la valeur des données et de révéler leur valeur par itération sans nécessité d’analyser de fond en comble l’intégralité des données métiers de l’entreprise.
- De simplifier dans le cadre d’organisation complexe, les rôles de la chaine d’acteurs impliquées par des données métiers pour démarrer un projet data. Le propriétaire de la donnée est défini dès la création de la donnée.
- De gagner en réactivité en cas d’évolution, de maintenance ou de problème opérationnel sur un périmètre de donnée métier : chaque domaine est autonome dans ses activités de données.
Data Mesh vs Datalake : que devient le datalake ?
Un datalake est une plateforme data qui vise à collecter, à stocker au même endroit l’ensemble des domaines des données métiers de l’entreprise et à les partager à l’ensemble des utilisateurs de l’entreprise quels que soient les métiers. L’architecture de la plateforme est conçue pour être scalable à moindre coût sans compromettre les performances.
Le Datalake est géré par une équipe en charge de transformer les données opérationnelles en produit « données » afin de les rendre exploitable pour chaque métier de l’entreprise.
Cette équipe centrale doit avoir la capacité à comprendre et à retranscrire tous les métiers de l’entreprise pour implémenter les produits. Elle doit avoir la capacité de suivre le rythme des demandes d’évolution adressées par les métiers, de collecter l’ensemble des données de l’entreprise et également à mettre en place des dispositifs d’amélioration de la qualité des données en collaboration avec les sources de données référentes.
Cette architecture de données qui repose sur une seule et unique technologie, peut constituer un frein à l’agilité dans le cadre de projet de montée de version ou de migration technologique. Une seule équipe, responsable de toutes les fonctions, est-elle en capacité de passer à l’échelle ?
Mais le Data Mesh et le Datalake peuvent se compléter. Les cas d’usage permettent de définir des frontières délimitées sur le positionnement de ces deux approches de conception d’architecture Data. Elle se complète si l’on considère notamment les cas d’usage lié à l’innovation des données, l’historisation, l’archivage des données et la data science.
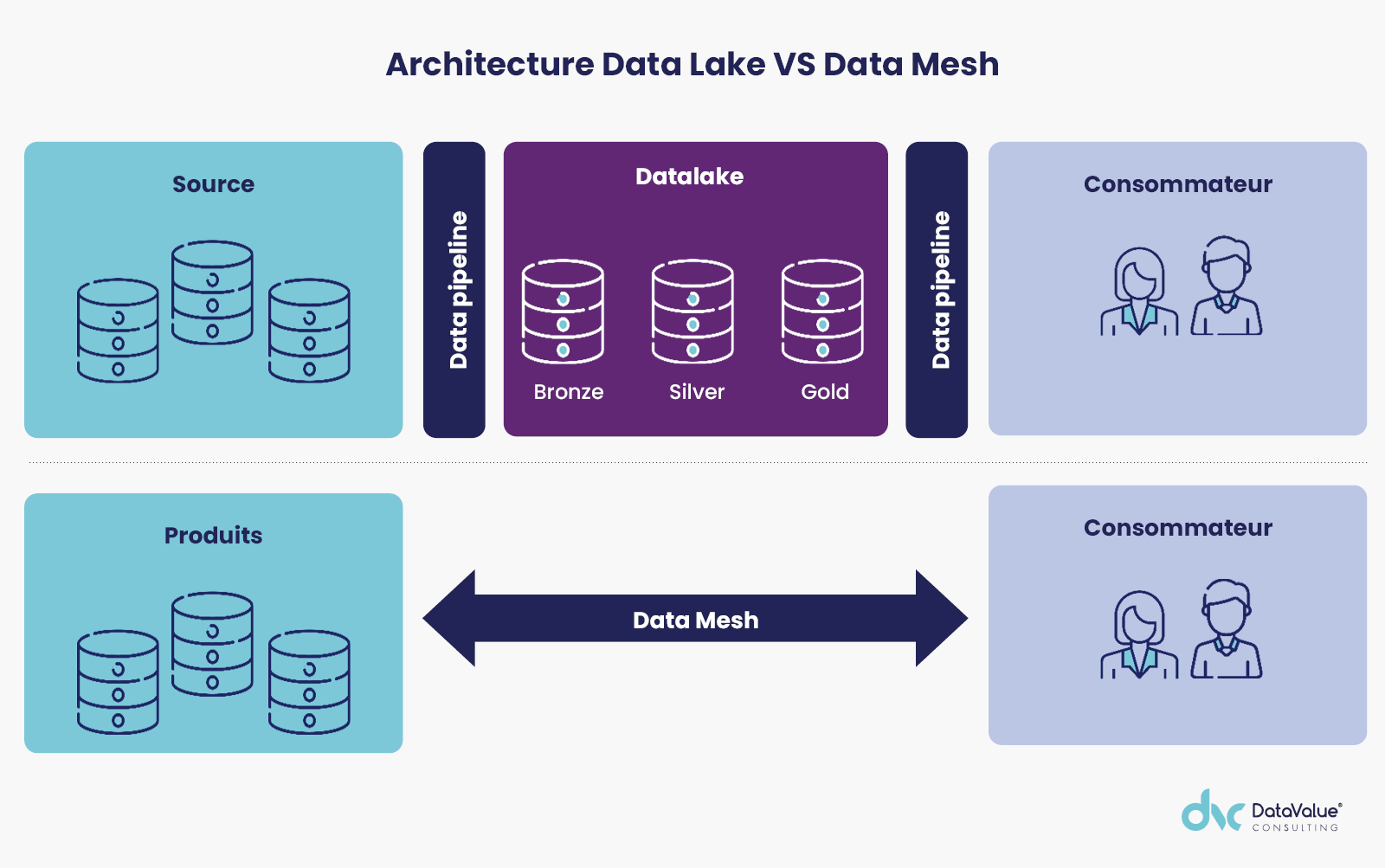
A-t-on vraiment besoin de Data Mesh ?
Le Data Mesh peut constituer une étape permettant d’initier une transformation de l’organisation des données en ciblant un premier périmètre de domaine de données à désiloter. Ce premier périmètre peut être choisi et priorisé en fonction de la création de valeur apportée. Le déploiement d’une couche d’interconnexion entre les domaines permettra de désiloter le premier périmètre identifié.
Le Data Mesh peut aider à mettre en place une gouvernance progressive au fur et à mesure de l’extension du périmètre des domaines désilotés sans impacter toute l’organisation de l’entreprise.
Le Data Mesh permet de découpler les technologies et les données par domaine. Elle apporte de la souplesse dans le cas de nouvelles orientations technologies ou de migration technologique sur les architectures de données.
Néanmoins, le Data Mesh implique un changement de culture d’entreprise pour ancrer la notion de domaine (qui induit la nomination de responsable de domaine, également responsable de la gouvernance de ses données, de sa qualité, de sa sécurité et de sa promotion) et la notion de produit (qui induit la prise en compte en continu des feedbacks des utilisateurs dans son développement).

Par Pascal Porsan
Directeur Architecture et Cybersécurité chez DataValue Consulting
