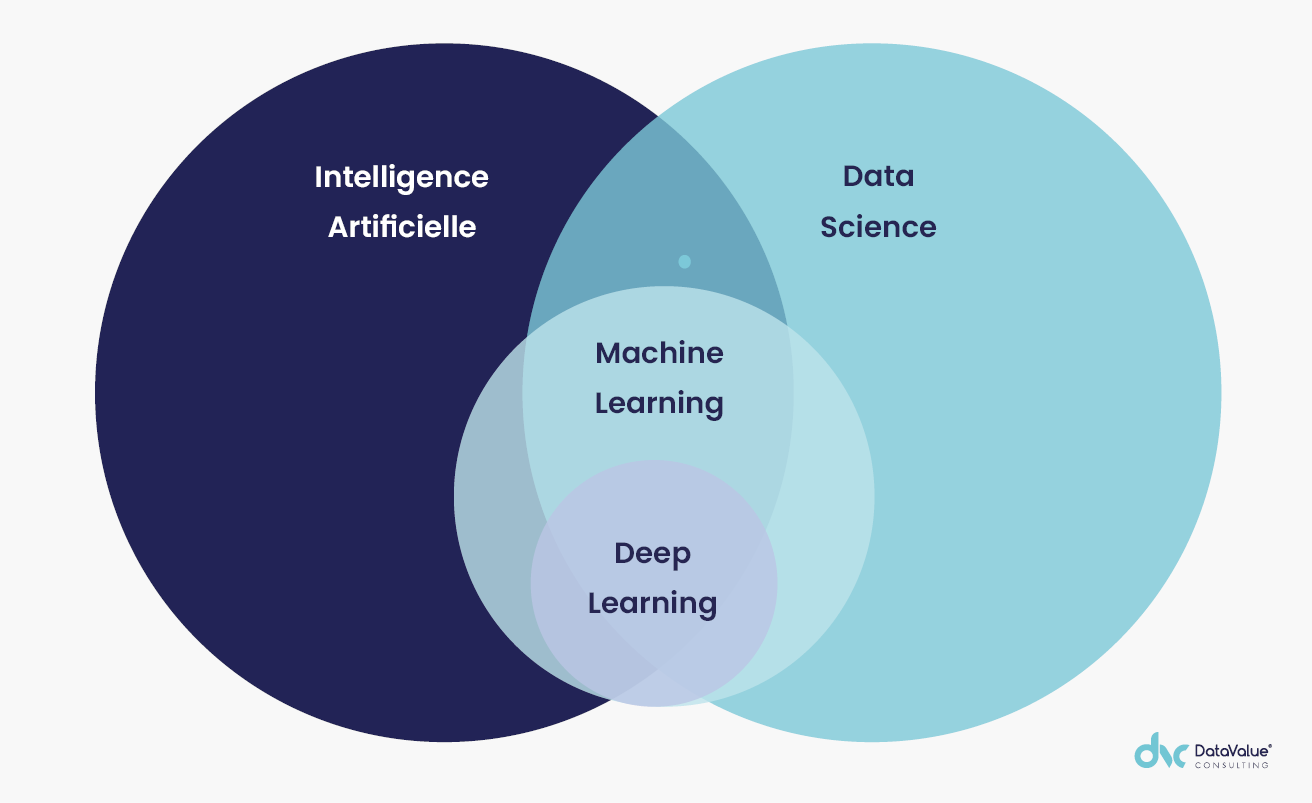
Les techniques de la Data Science, de l’Intelligence Artificielle, du Machine Learning et du Deep Learning se croisent, s’alimentent et poursuivent parfois le même objectif. Ces démarches restent néanmoins des disciplines à part entière, chacune d’elles se matérialisant par des outils et réalisations dédiés.
Les concepts et frontières étant parfois flous, nous nous attacherons à apporter un éclairage sur les différentes approches et finalités de ces disciplines.

L’intelligence Artificielle : réalité ou fiction ?
Le terme d’Intelligence Artificielle est un concept qui mobilise différents types de systèmes mais ne répond actuellement à aucune définition universelle. Le concept n’opère aucune dichotomie entre les IA dites « fortes » ; systèmes relevant de la science-fiction, et les IA « faibles » ; systèmes opérationnels en capacité d’exécuter des tâches complexes. (Ex : chatbot).
Le terme peut néanmoins être défini comme l’ensemble des théories et techniques orchestrées en vue de mettre en place des machines capables de simuler l’intelligence humaine. Ainsi, l’IA vise à reproduire au mieux les activités mentales et intellectuelles humaines : la compréhension, la perception et la prise de décision.
A la croisée de l’informatique, de l’électronique et des sciences cognitives, la discipline est distincte de l’informatique qui traite, trie et stocke les données et leurs algorithmes.
L’IA a permis aux chercheurs de produire des réalisations spectaculaires et se ventile en 3 grandes catégories :
- L’Artificial Narrow Intelligence :
L’intelligence artificielle faible qui est un système d’intelligence artificiel ciblé sur une tâche étroite voire unique. L’ANI consiste en l’automatisation d’une tâche, d’un domaine. A titre d’exemple les chatbots (détaillés ci-dessous)
- Artificial General Intelligence :
L’AGI revoit à un type d’IA qui est aussi capable qu’un humain, ou presque. A titre d’exemple, abstraction faite des matérialisations éventuelles, ces systèmes devraient être capables d’identifier/ comprendre, ressentir et exprimer, à juste mesure, des émotions telles que l’empathie. Les dernières réalisations en la matière type Bina 48 et Sophie de Hanson Robotics sont très controversées au sein de la communauté des experts en IA. En effet, ces robots humanoïdes sont vraisemblablement en mesure d’échanger avec l’humain mais leur intelligence reste très faible et les réponses qu’ils formulent parfois, manifestent clairement leur absence totale de compréhension de la question adressée par l’interlocuteur.
- Artificial Super Intelligence
L’ASI en est encore à ses prémices et ne verra d’applications concrètes que dans un certain temps. Ce type d’IA devra être en mesure de surpasser les capacités humaines et d’extraordinairement performer dans les domaines tels que la prise de décision, les relations émotionnelles ou les arts.
La seule IA déployée de nos jours est l’ANI. En effet et à titre d’exemple, nous interagissons quotidiennement avec ce type de systèmes, en utilisant Siri, Alexa ou encore les chatbots. Ces derniers sont des agents conversationnels optimisés par apprentissage profond, et ce afin de mieux répondre aux demandes adressées par les clients. Ces technologies interagissent et communiquent avec les humains de manière personnalisée et naturelle en utilisant le traitement automatique du langage naturel (NLP).
Souvent désignés comme tels, le Machine Learning ainsi que le Deep Learning sont des sous-ensembles de l’IA et non pas des concepts équivalents. Ces méthodologies de traitements de la donnée sont par ailleurs, des sous domaines de la Data Science.
Qu’est-ce que la Data Science ?
La Data Science est un vaste domaine qui regroupe les méthodologies et outils inhérents à la collecte, la gestion et l’analyse de données. Cette discipline permet la création de valeur à partir de l’exploration et l’analyse de données brutes.Il s’agit d’un mélange disciplinaire englobant une large variété de techniques telles que la programmation informatique, les mathématiques ou les statistiques.
La réalisation d’un projet de data science respecte généralement un schéma de traitement standard, ajustable à tout niveau, selon les besoins, la maturité ainsi que la faisabilité de mise en place.
Le processus débute généralement par de la collecte de données ou la mise en place d’un espace de stockage dédié (lorsque cela est nécessaire et/ ou possible). Après que la disponibilité des données ait été assurée, les phases de découverte et de nettoyage des données peuvent débuter. Bien que chronophages, ces étapes sont indispensables et constituent de vrais prérequis à la mise en place de la modélisation, cœur du projet. Faisant suite à de nombreuses itérations, un choix de méthodologie et d’algorithme de modélisation sera réalisé pour enfin déployer un modèle éprouvé. A titre d’exemple, la data science permet aux entreprises d’optimiser la fidélisation de la clientèle ou encore de prédire les résultats financiers.
Comme précédemment évoqué, le Machine Learning ainsi que le Deep Learning sont à la fois des sous-ensembles de la Data Science et de l’IA. Intéressons-nous de plus près à ces deux disciplines !
Qu’est-ce que le Machine Learning ?
Apprentissage automatique basé sur l’expérience, le Machine Learning est un système qui fonctionne à partir d’algorithmes qui, alimentés de données, tendent à apprendre et à s’améliorer automatiquement. Les processus d’apprentissage et d’amélioration continue se font à partir de l’expérience et non pas grâce à une programmation.
Ainsi, l’apprentissage consiste à traiter des observations ou des données (des exemples, une expérience ou des instructions) dans le but de rechercher des modèles permettant la mise en place de prédictions et la prises de décisions.
Les algorithmes de Machine Learning s’exécutent selon différents apprentissages et produisent des modèles d’algorithmes spécifiques. Ci-dessous, nous détaillions les 3 grandes familles d’apprentissage :
- L’apprentissage supervisé: Les algorithmes de Machine Learning supervisés peuvent appliquer ce qui a été appris dans le passé à de nouvelles données en utilisant des exemples étiquetés pour prédire des événements futurs. Cette méthodologie d’apprentissage permet la construction d’une fonction de prédiction à partir d’exemples.
- L’apprentissage non supervisé: Ses algorithmes apprennent à partir de données d’essai qui n’ont pas été étiquetées, classées ou catégorisées. Cette approche permet de trouver une structure dans les données, comme le regroupement ou le clustering.
- L’apprentissage semi-supervisé: Les algorithmes de Machine Learning semi-supervisés se situent entre l’apprentissage supervisé et non supervisé. Ils utilisent à la fois des données étiquetées et non étiquetées pour l’apprentissage.
Le Machine Learning est utilisé dans différents secteurs pour répondre à diverses problématiques. A titre d’exemple, grâce à cette discipline, il devient aisé d’identifier des opportunités d’investissement en calibrant les systèmes de négociation, de proposer des recommandations précises et personnalisées aux consommateurs, ou encore de lutter contre la fraude.
> À LIRE AUSSI : Découverte du Machine Learning avec Python et le Framework Ray
Qu’est-ce que le Deep Learning ?
Le Deep Learning est un sous domaine ou un type d’intelligence artificielle. Il s’agit d’un dérivé du Machine Learning, où la machine est qualifiée d’intelligente car capable d’apprendre par elle-même.
L’apprentissage profond, repose sur le traitement de quantités massives de données et ce, grâce à des réseaux de neurones artificiels dont la structure imite celle du cerveau humain. Ces réseaux sont composés de centaines de « couches » de neurones, chacune recevant et interprétant les informations de la couche précédente. Plus le nombre de neurones est élevé, plus le réseau est dit « profond ».
Le Deep Learning est déjà utilisé dans un certain nombre de secteurs et investit de nombreux aspects de notre vie courante à savoir : la reconnaissance d’images, les voitures autonomes, la modération automatique des réseaux sociaux, les chatbots …
Bien que le Machine Learning et le Deep Learning aient un objectif partagé, à savoir l’extraction d’insights facilitant la prise de décision, leurs approches et bénéfices respectifs restent différents. En effet, le Machine Learning, à l’instar des statistiques, adopte une approche permettant la compréhension de la structure des données. Le Deep Learning quant à lui permet de combiner des avancées technologiques (puissance informatique et réseaux de neurones artificiels) afin d’apprendre des patterns complexes au sein de quantités massives de données.
La rédaction vous conseille
> Les bonnes pratiques pour assurer la qualité des données
> Master Data Management : la gestion du référentiel des données
