Récemment, la disponibilité des données et l’amélioration considérable des puissances de calcul des GPU ont rendu l’apprentissage en profondeur, « Deep Learning », populaire par rapport aux autres techniques d’apprentissage automatiques. Un modèle de Deep Learning est simplement un modèle empilant un large nombre de couches de différents types de réseaux de neurones.
Dans cet article, nous allons étudier un type particulier de réseaux de neurones : les réseaux de neurones récurrent ou RNN (Récurrent Neural networks). Il s’agit d’une classe de réseaux de neurones parfaitement adaptée aux données séquentielles. L’article sera détaillé comme suit :
- Présentation en détail des réseaux de neurones récurrents, de leurs utilisations ainsi que de leurs limitations.
- Présentation d’une variante de ces réseaux appelée LSTM (Long Short Term Memory), les motivations derrière son introduction ainsi que son avantage par rapport aux RNN classiques.
- Présentation de la variante GRU en détail.
- Conclusion de ce travail.

Les réseaux de neurones récurrents (RNN)
Les réseaux de neurones récurrents RNN [1], sont un type de réseau de neurones largement utilisé dans le domaine de l’apprentissage en profondeur (Deep Learning) [2] [3] [4]. Les RNN utilisent les sorties précédentes comme entrées supplémentaires et sont parfaitement adaptés au traitement de données séquentielles. Généralement, elles se présentent sous la forme suivante :

Figure 1 : Architecture RNN traditionnelle. Source : stanford.edu
À chaque instant t, le passage vers l’avant (forward pass) est modélisé par les équations suivantes :

Où xt et at sont respectivement le vecteur d’entrée du réseau et le vecteur d’activation à l’instant t, g1, g2 sont des fonctions d’activation, les W et b sont respectivement les poids et les biais à apprendre durant l’entrainement du réseau.
La valeur de sortie à l’instant t y<t> est calculée par l’équation (2) en fonction de la valeur d’activation a<t> calculée par l’équation (1).
Nous constatons clairement l’aspect récurrent dans ces calculs (le calcul à l’instant t est à base de l’information apportée de l’instant t-1, elle-même calculée à partir de l’information apportée de t-2 etc.), contrairement à un réseau de neurones classique ANN (Artificial Neural Network) où la sortie dépend uniquement des valeurs d’entrées. La figure 2 illustre bien cette différence :
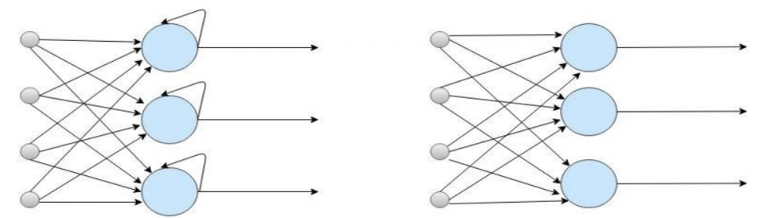
Figure 2 : ANN Vs RNN. Source : Medium
Bien que les RNN sont très pratiques comparé à une architecture ANN classique pour le traitement des données séquentielles, il s’avère qu’ils sont extrêmement difficiles à entraîner pour gérer la dépendance à long terme [5] en raison du problème de la disparition du gradient (Gradient Vanishing). Une explosion de gradient peut également se produire mais très rarement. Pour surmonter ces lacunes, de nouvelles variantes RNN ont été introduites dans la littérature. C’est l’objet des sections suivantes.
Long short term memory LSTM
Pour surmonter le problème du vanishing du gradient, le LSTM est proposé initialement par S. Hochreiter et al [6], puis amélioré dans l’article de F. Gers et j. Schmidhuber [7]. L’unité LSTM illustré dans la figure 3 est le composant de base d’une architecture LSTM. C’est une série de portes et de cellules qui coopèrent pour produire un résultat final. Un passe avant LSTM est modélisé par les équations (3-8)
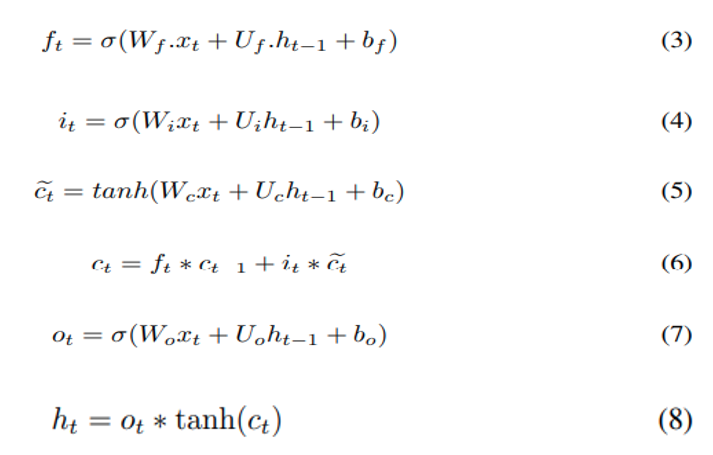
Où σ est la fonction sigmoïde, ft est le vecteur d’activation de porte d’oubli (Forget gate), it vecteur d’activation de porte d’entrée, ot vecteur d’activation de porte de sortie, vecteur d’activation d’entrée de cellule, ct état de la cellule, ht vecteur de sortie de l’unité LSTM, tous les W et U sont des poids, b est un vecteur de biais et le symbole * pour le produit hadamard. Poids W, U et les biais b doivent être appris durant le processus d’entrainement.
Commençons par l’état de la cellule ct qui contient deux types d’informations :
- les anciennes informations à conserver de l’état précédente ct-1 , ajustée à l’aide de la porte d’oubli ft qui décide du pourcentage d’informations à conserver en calculant une valeur comprise entre 0 (jeter complètement) et 1 (garder complètement),
- les nouvelles informations à inclure dans l’état de la cellule calculée à l’aide de la porte d’entrée it et de l’activation de la cellule ceux qui sont calculés respectivement à l’aide des équations 4 et 5.
La valeur finale est ensuite calculée en deux parties, premièrement une valeur candidate via l’équation 7 cette valeur sera ajustée en fonction de la valeur de la cellule mémoire pour produire le résultat final.
L’utilisation de l’état de la cellule dans le calcul final rend le LSTM très puissant dans des tâches où les informations doivent être stockées et utilisées ultérieurement (dépendance long terme). La modélisation du langage est un exemple simple illustrant ce cas de figure, en effet le sujet au début de la phrase décide de la conjugaison du verbe à utiliser au milieu ou même à la fin de la phrase.
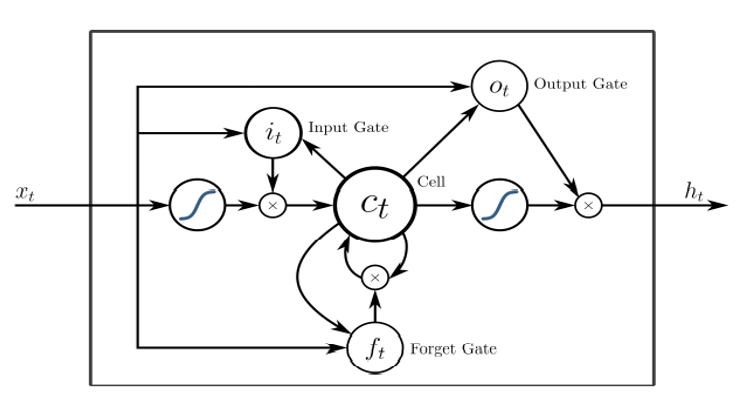
Figure 3 : Unité de base LSTM. Source : Wikimedia
Gated Recurrent Unit (GRU)
L’unité récurrente fermée GRU (Gated Recurrent Unit) a été introduite en 2014 par Cho et Al [8] pour résoudre le problème de disparition du gradient rencontré par les réseaux récurrents classiques mais aussi pour proposer une architecture avec moins de paramètres à entrainer par rapport à une LSTM. À l’instar de LSTM, l’unité GRU est l’élément de base d’une architecture GRU. Une passe avant de l’unité GRU est modélisé par les équations (9-12) :

où σ est la fonction sigmoïde, zt est le vecteur d’activation de la porte de mise à jour, rt le vecteur d’activation de la porte de réinitialisation, het le vecteur candidat et ht est le vecteur output de l’unité GRU. W et U sont des poids, b est le vecteur biais (poids et biais sont à entrainer durant le processus d’apprentissage) et le symbole * pour le produit de Hadamard.
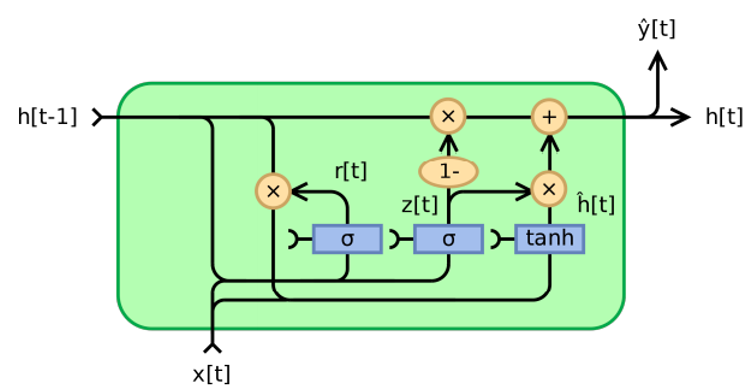
Figure 4 : Unité de base GRU. Source : Wikimedia
Conclusion sur les RNN
Dans cet article, nous avons présenté une vue d’ensemble des réseaux de neurones récurrents classiques ainsi que leurs deux variantes les plus populaires et les plus utilisées : LSTM et GRU. Cette introduction technique est primordiale pour pouvoir se lancer dans une série d’articles sur les différents cas d’usage dans le monde de l’entreprise que nous vous présenterons très prochainement.
Sources :
[1] Rumelhart DE, Hinton GE, Williams RJ (1986) Learning representations by backpropagating errors. Nature 323 :533–536.
[2] LeCun Y, Bengio Y, Hinton G (2015) Deep learning. Nature 521 :436–444
[3] Schmidhuber J (2015) Deep Learning in Neural Networks : An Overview. Neural Networks 61 :85–117.
[4] Goodfellow I, Bengio Y, Courville A (2016) Deep learning. MIT Press.
[5] Bengio Y, Simard P, Frasconi P (1994) Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks 5 :157–166.
[6] Hochreiter S, Schmidhuber J (1997) Long Short-Term Memory. Neural Computation 9 :1735–1780.
[7] Gers F, Schmidhuber J, Cummins FA (2000) Learning to Forget : Continual Prediction with LSTM. Neural Computation. https ://doi.org/10.1162/089976600300015015.
[8] Cho K, van Merrienboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, Bengio Y (2014) Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv :1406.1078.
La rédaction vous conseille
> L’Infrastructure as Code comme accélérateur de Delivery
> Découverte du Machine Learning avec Python et le Framework Ray
