1. Qu’est-ce qu’un data lake ?
Un data lake est un référentiel de données permettant de stocker une large quantité de données brutes dans leur format natif pour une durée indéterminée. Cette méthode de stockage permet de faciliter la cohabitation entre les différents schémas et formes structurelles de données, généralement des blobs (Binary Large Object) ou des fichiers.
Au sein d’un seul data lake, toutes les données de l’entreprise sont stockées. Les données brutes côtoient les données transformées. Ces données sont ensuite utilisées pour établir des rapports, pour visualiser les données, pour l’analyse de données ou pour le Machine Learning.
Le data lake regroupe les données structurées en provenance de bases de données relationnelles en couloir ou en colonne, les données semi-structurées telles que les CSV, les logs, les XML, les JSON, et les données non structurées telles que les emails, les documents et les PDF. On y trouve même des données binaires telles que des images, des fichiers audios ou des vidéos.
2. Les défis de l’hébergement d’un data lake on-premise
Complexité de la création de pipelines de données : en créant une infrastructure on-premise, on doit généralement gérer à la fois l’infrastructure matérielle (mise en marche des serveurs, orchestration des travaux ETL par lots, gestion des pannes et des temps d’arrêt) et logicielle. Cela exige que les data ingénieurs intègrent une large gamme d’outils pour ingérer, organiser, prétraiter et interroger les données stockées dans le data lake.
Coûts de maintenance : mis à part l’investissement initial nécessaire pour acheter des serveurs et des équipements de stockage, il existe des coûts de gestion et d’exploitation continus lors de l’exploitation d’un data lake on-premise, se manifestant principalement par des coûts informatiques et d’ingénierie.
Évolutivité : si l’on souhaite faire évoluer le data lake pour prendre en charge davantage d’utilisateurs ou des données plus volumineuses, on doit ajouter et configurer manuellement des serveurs. On doit aussi surveiller de près l’utilisation des ressources et tout serveur supplémentaire entraîne des coûts de maintenance et d’exploitation supplémentaires.

3. Les 6 raisons de migrer vers un data lake sur le cloud
3.1. Concentration sur la valeur commerciale et non sur l’infrastructure
L’utilisation du cloud pour stocker des données volumineuses élimine le besoin de créer et de maintenir une infrastructure. Ainsi, les ressources financières peuvent être allouées à l’ingénierie afin de développer de nouvelles fonctionnalités qui dégageront de la valeur métier plus rapidement.
3.2. Réduction des coûts d’ingénierie
Des pipelines de données peuvent être créés plus efficacement avec des outils cloud. Le pipeline de données est souvent pré-intégré, on peut donc obtenir une solution fonctionnelle sans investir des centaines d’heures dans l’ingénierie des données.
3.3. Utilisation des services gérés pour évoluer
Le fournisseur cloud peut gérer la mise à l’échelle à notre place. Certains services cloud de data lake tels qu’Amazon S3 et Athena fournissent une mise à l’échelle totalement transparente : aucun besoin d’ajouter des machines ou de gérer des clusters.
3.4. Une infrastructure agile
Les services cloud sont flexibles et offrent une infrastructure à la demande. Si de nouveaux cas d’utilisation se présentent pour votre lac de données, la réorganisation du data lake se fait plus facilement.
3.5. Des technologies à jour
Les data lakes basés sur le cloud se mettent à jour automatiquement et mettent les dernières technologies à votre disposition. On peut également ajouter de nouveaux services cloud au fur et à mesure de leur disponibilité, sans modifier votre architecture.
3.6. Fiabilité et disponibilité
Les fournisseurs cloud s’efforcent d’éviter les interruptions de service, en stockant des copies redondantes des données sur différents serveurs. La disponibilité couvre plusieurs centres de données. Amazon S3, par exemple, promet « 99,99999999999 % » de durabilité des données.
4. Comparaison d’architecture data lake on-premise Vs architecture data lake cloud AWS (exemple issu de production)
4.1. Architecture on-premise
Voici un exemple d’une architecture d’un data lake on-premise :
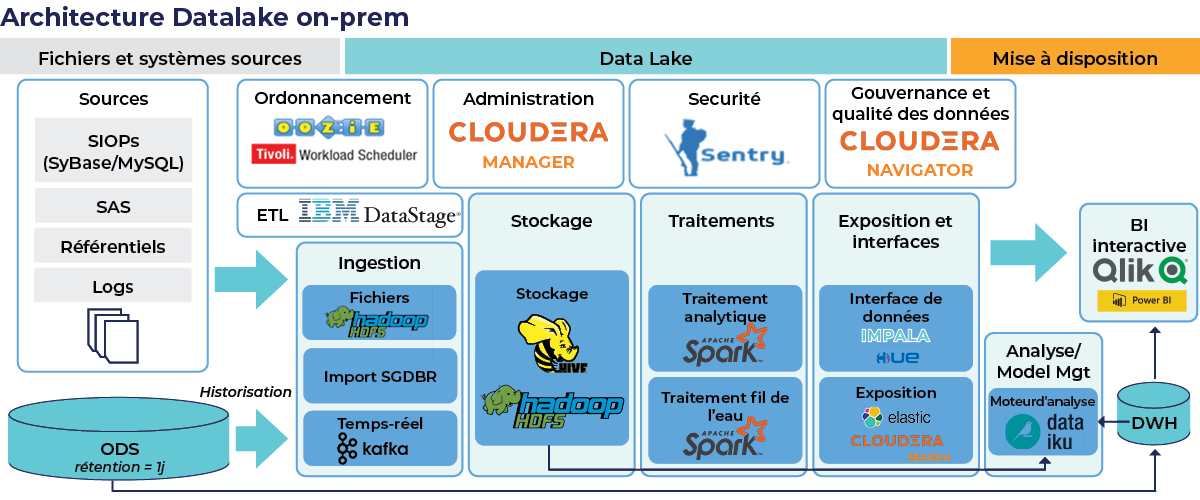
Couche Infrastructure :
Dans cet exemple, la plate-forme on-premise est exécutée sur Cloudera 5.9. La plate-forme se compose de 15 hôtes, ayant 106 To de stockage et 2 To de RAM. Chaque hôte a au moins 3 rôles, les rôles sont soit des services Cloudera, des services de science des données ou des services API.
Couche Monitoring et administration de l’infrastructure :
Le monitoring et l’administration se font avec Cloudera Manager, un outil disposant d’une interface graphique intuitive afin de faire les déploiements avec des fonctionnalités de suivi. Ceci permet de recevoir des alertes en cas d’erreur.
Couche Sources de données :
Le data lake on-premise se source de données internes, externes (partenaires) et d’open data. Le data lake reçoit tout type de données :
- Structurées: des tables issues des bases de données relationnelles (MySQL, SyBase, SqlServer)
- Semi-structurées: des fichiers CSV, TXT, JSON, XML, PARQUET.
- Non-structurées: des fichiers MP3, JPEG, PDF
Couche Stockage :
Le stockage des données sur les plateformes on-premise est fait sur le HDFS (Hadoop Distributed File System). Il est organisé selon des normes fonctionnelles et ne fait pas de différences entre les types des fichiers (HDFS peut stocker tout type de données mentionnées ci-dessus).
Couche Ingestion :
L’ingestion sur le data lake on-premise se faisait de deux façons :
- SQOOP : un outil Apache qui vient avec le stack Cloudera et qui permet la connexion entre Hadoop et les bases de données relationnelles. Ce type d’ingestion est principalement réalisé à partir des données internes, vu la facilité d’obtention des accès et la simplicité d’ingestion qu’il offre. Les Tables sont donc copiées du SGBD vers le HDFS et sont exposées sur le Hive MetaStore.
- Ingestion par script : les données semi structurées et non structurées sont déposés sur un Network-attached storage (NAS), attaché à la plateforme cloudera.
Ces données sont consommées par le script d’ingestion à leurs réceptions sur le NAS et sont déposées dans le HDFS et exposées dans le Hive MetaStore.
Couche Traitement :
Les traitements de données se font sur Spark, Hive et Impala. Le moteur d’exécution de ces jobs est YARN. Les traitements sont en forme de : préparation, chargement et exposition de données.
Couche Mise à disposition :
Une fois prêtes à être exposées, les données sont mises à disposition pour les services de :
- Data Science via l’outil Data Science Studio (DSS). Cet outil offre une vue sur une partie du HDFS et contient les données demandées par les data scientists. DSS a le pouvoir d’opérer des traitements en Spark, Hive et Impala qui répondent aux besoins de machine learning et d’analyse de données des métiers. Ces traitements sont gérés par YARN, le manager de ressource cloudera.
- Data Visualisationvia des connexions ODBC entre Impala et Microsoft PowerBI
4.2 Architecture cloud
Voici un exemple d’une architecture d’un data lake cloud :
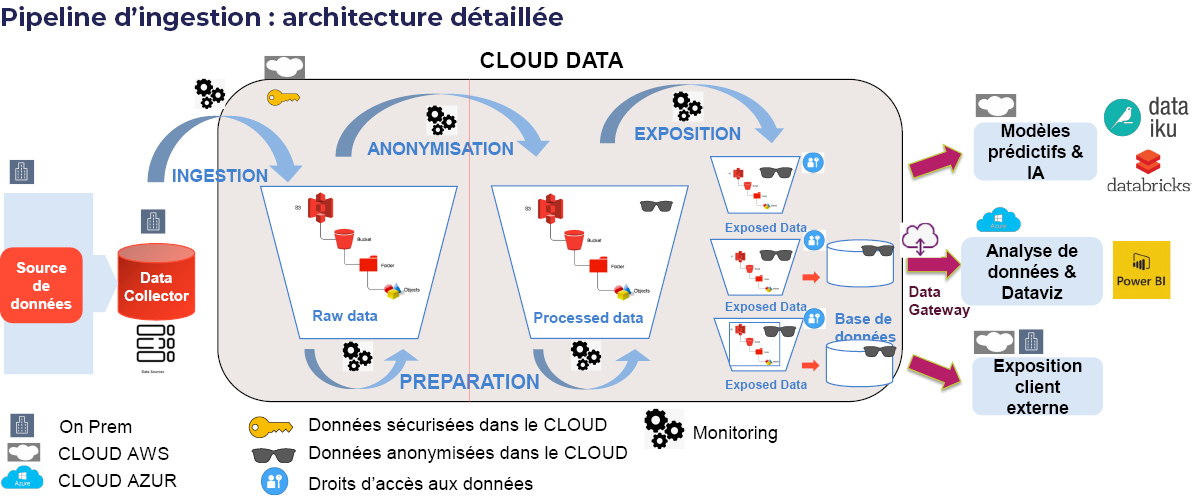
Couche Observabilité et Monitoring :
Etant donné que l’architecture cloud est distribuée, il est nécessaire d’avoir une vue d’ensemble du système. Différents outils permettent de surveiller les différentes parties du datalake.
- Monitoring de l’infrastructure et des traitements
Le suivi de l’état de l’infrastructure est effectué avec le service AWS cloudWatch qui est dédié au monitoring des autres services qui effectuent des actions sur les données (tels que EC2 ou Redshift). La console du service permet de suivre la consommation des ressources en temps réel.
Des alertes peuvent être programmées et remontées (par mail, sms, etc.), ce qui favorise la fiabilité et la haute disponibilité de l’infrastructure pour les utilisateurs.
CloudWatch est aussi le service utilisé pour stocker et lire les logs des traitements issus des services de data processing (EC2,Glue, DynamoDB …etc).
- Monitoring du compte AWS
En plus du monitoring de l’infrastructure, AWS offre le service CloudTrail pour le suivi administratif du compte utilisé.
AWS CloudTrail procure une visibilité sur l’activité des utilisateurs par le biais de l’enregistrement des actions effectuées sur le compte. CloudTrail enregistre des informations importantes pour chaque action dont : l’identité de la personne ayant effectué la demande, les services utilisés, les paramètres des actions ainsi que les éléments de réponse renvoyés par le service AWS.
Ces informations permettent de suivre les modifications apportées aux ressources AWS et de résoudre les problèmes opérationnels. CloudTrail facilite la mise en conformité avec les politiques internes et les normes réglementaires.
Couche Sources de données :
Comme le data lake on-premise, le data lake sur le cloud se source de données internes, externes (partenaires) et d’open data.
Le data lake reçoit tout type de données :
- Structurées: des tables issues des bases de données relationnelles (MySQL, SyBase, SqlServer)
- Semi-structurées: des fichiers CSV, TXT, JSON, XML, PARQUET.
- Non structurées: des fichiers MP3, JPEG, PDF.
Couche Stockage :
Le stockage des données est fait sur le service AWS : Simple Storage Service (S3). Ce stockage sur le cloud est organisé en cascade :
« Raw Data » => « Processed Data » => « Exposed Data ».
- Raw Data: un bucket S3 qui sert d’espace de stockage des données brutes chiffrées. Aucun accès direct n’est autorisé sur ces données.
- Processed Data: un bucket S3 qui sert d’espace de stockage des données transformées (chiffrées et anonymisées). Aucun accès direct n’est autorisé sur ces données.
- Exposed Data : un bucket S3 qui sert d’espace de mise à disposition des données (chiffrées et anonymisées). Les utilisateurs du data lake peuvent accéder aux données de ce bucket en fonction des droits prédéfinis.
Couche Ingestion :
Contrairement au data lake on-premise, le data lake sur le cloud ne se source que par fichiers.
Le mécanisme consiste en un dépôt des fichiers via SFTP dans une zone d’acquisition de données (Data Collector dans le schéma) qui servira de hub entre les producteurs et les consommateurs de données.
Le data collector va solliciter la dynamo DB déjà alimentée afin d’obtenir les TAGS techniques et fonctionnels des fichiers qui serviront comme clés d’arborescence en stockant sur le « Raw data ».
Couche Anonymisation :
C’est un traitement Spark Scala tournant sur AWS GLUE qui réalise une anonymisation chiffrée sur des données à caractère personnel (nom, prénom, adresse …etc.) identifiées et renseignées dans la configuration du traitement. Les données chiffrées peuvent être déchiffrées exceptionnellement (besoin marketing, RH…etc..) dans l’espace « Exposed Data ».
Couche Traitements :
Les traitements de préparation de données se font principalement sur 2 services :
- AWS Glue : via des jobs Spark Scala sur des données cataloguées dans le catalogue de données GLUE qui s’alimente sur les données dans le bucket « S3 : Raw Data ».
La sortie de ces traitements est écrite sur « S3 : Raw Data » avec une clé Processed qui permet d’identifier qu’il s’agit d’un traitement de préparation de données.
L’écriture se fait sur « Raw Data » afin que le résultat du data-préparation soit également anonymisé et déposé sur « Processed Data ».
- AWS Redshift : à partir de jobs SQL exécutés sur des données importées depuis le bucket « S3 : Raw Data », comme sur Glue, les résultats sont écrits sur « S3 : Raw Data » avec une clé Processed qui permet d’identifier que c’est un traitement de préparation de données.
La sortie de ces traitements, comme tous les datasets, est anonymisée et écrite sur le bucket « S3 : Processed Data ».
Couche Mise à disposition :
Les données prêtes à être exposées sont placées sur le bucket « Exposed Data » à destination des services de :
- Data Science via l’outil Data Science Studio (DSS) :
Chaque Use-Case possède son propre espace « Exposed Data ». Chaque Use-Case ne peut consulter et utiliser que les données le concernant. Celles-ci sont demandées en amont et un Use-Cases n’a donc pas les droits pour accéder aux données des autres Use-Cases. DSS a le pouvoir d’opérer des traitements en sparkSQL, Spark Scala, PySpark, Python, R et SHELL. Ces traitements répondent aux besoins de machine learning et d’analyse de données des métiers. Les traitements distribuées (SPARK) sont gérés par DataBricks.
- Data Visualisation :
Les tables / fichiers demandés par le service de data visualisation sont importés sur AWS Athena qui est connecté à Azure PowerBI.
5. Récapitulatif sur les services utilisés
5.1. Infrastructure
AWS Virtual Private cloud (VPC) permet de mettre en service une section du cloud isolée de manière logique, au sein de laquelle on peut lancer des ressources AWS dans un réseau virtuel défini par les utilisateurs.
Les utilisateurs du VPC ont la totale maîtrise de l’environnement de mise en réseau virtuel, y compris pour la sélection des plages d’adresses IP, la création de sous-réseaux et la configuration de tables de routage et de passerelles réseau. Un VPN peut être mis en place entre le on-premise et le VPC afin d’interconnecter les deux.
AWS Elastic Compute cloud (EC2) est le service utilisé pour la création des différents serveurs utilisés dans le projet.
Amazon EC2 permet d’obtenir et de démarrer des instances de serveurs de différentes tailles selon le besoin en quelques minutes, puis d’augmenter ou de diminuer rapidement leurs capacités en fonction de l’évolution des besoins de calcul.
TerraForm est outil permettant de créer, de modifier et de gérer l’infrastructure de manière sûre et reproductible. Les opérateurs et les équipes d’infrastructure peuvent utiliser Terraform pour gérer les environnements avec un langage de configuration appelé HashiCorp Configuration Language (HCL) pour des déploiements automatisés et lisibles par l’homme.
Terraform est un outil open source et peut être utilisé pour tout type de cloud (AWS, AZURE, GCP …etc.)
5.2. Stockage des données
AWS Simple Storage Service S3 est un service de stockage d’objets conçu pour stocker et récupérer n’importe quelle quantité de données. Il s’agit d’un service de stockage simple qui offre une durabilité, une disponibilité, des performances, une sécurité et une scalabilité virtuellement illimitée à la pointe de l’industrie pour un tarif très bas.
5.3. Base de données
AWS RDS Relational Database Service est un service géré qui facilite la configuration, l’utilisation et le dimensionnement d’une base de données relationnelle dans le cloud. Ce service fournit une capacité économique et redimensionnable, tout en gérant les longues tâches d’administration de base de données.
Amazon RDS donne accès aux capacités d’une base de données classique MySQL, MariaDB, Oracle, SQL Server ou PostgreSQL. Ceci signifie que le code, les applications et les outils déjà utilisés aujourd’hui dans les bases de données existantes devraient fonctionner de manière transparente avec Amazon RDS.
AWS Athena est un service de requête interactif qui facilite l’analyse des données dans Amazon S3 à l’aide de la syntaxe SQL standard. Athena est service qui est serverless (ne requiert aucun serveur) et peut être opérationnel immédiatement, sans avoir à configurer ni gérer d’infrastructure. Il n’est même pas nécessaire de charger les données dans Athena puisque le service accède directement aux données stockées dans S3.
Athena est également utilisé comme le service d’interconnexion avec les outils de data-viz (MSPowerBI).
AWS Redshift est le service warehouse du cloud. Il est utilisé pour sa capacité à exécuter des requêtes analytiques complexes sur quelques téraoctets ou plusieurs pétaoctets de données structurées ou semi-structurées en utilisant l’optimisation de requête sophistiquée, le stockage en colonnes hautes performances et l’exécution de requêtes massivement parallèles. AWS Redshift permet ainsi d’obtenir des résultats à la seconde, il est par conséquent utilisé pour la data-prep et la construction des datamarts complexes.
AWS DynamoDB est un service de base de données non relationnelle serverless, rapide et flexible, adaptable à tout type de structure.
5.4. Data Pipeline (processing)
AWS Lambda est un service serverless qui sert à exécuter du code pour pratiquement n’importe quel type d’application, sans aucune tâche administrative. Il suffit de charger le code et le service Lambda fait le nécessaire pour l’exécuter et le dimensionner en assurant une haute disponibilité.
Lambda peut exécuter du code écrit en : C#, Go, Java, Python, NodeJS, Ruby.
Appache AirFlow est un outil d’automatisation de flux de travail (workflows) open-source basé sur Python, utilisé pour configurer et gérer des pipelines de données. Airflow aide à gérer, structurer et organiser les pipelines ETL à l’aide de graphes acycliques dirigés (DAG).
AWS Glue est un service d’intégration serverless qui facilite la découverte, la préparation et la combinaison des données pour l’analytique, le machine learning et le développement d’applications. AWS Glue offre toutes les fonctionnalités nécessaires à l’intégration des données.
Le service propose des interfaces visuelles et codées pour faciliter cette intégration. Les utilisateurs peuvent facilement trouver et accéder aux données à l’aide du catalogue de données AWS Glue. Les data ingénieurs et les développeurs peuvent visuellement créer, exécuter et surveiller des flux de travail ETL en quelques clics dans AWS Glue Studio.
5.5. Sécurité
AWS Identity Access Manager (IAM) permet de contrôler de façon sécurisée l’accès aux ressources AWS pour les utilisateurs et groupes d’utilisateurs. IAM permet de créer et gérer des identités d’utilisateurs « utilisateurs IAM » et leur accorder des autorisations d’accès aux ressources AWS (les services, les données…etc.).
IAM permet également d’octroyer des autorisations à des utilisateurs en dehors d’AWS (utilisateurs fédérés).
5.6. Partie Finops
AWS Billing and Cost Management est le service utilisé pour payer les factures AWS, surveiller l’utilisation des multiples services, analyser et contrôler les coûts. Ce service Billing and Cost Management fournit des fonctionnalités qui peuvent être utilisées pour effectuer les opérations suivantes :
- Estimer et planifier les coûts AWS
A partir des mois précédents et de prévisions de charges sur l’infrastructure, il est en effet possible d’avoir une idée des coûts pour chaque service dans le temps.
- Recevoir des alertes si les coûts dépassent un seuil défini
Il est en effet possible de placer des seuils afin d’être alerté en temps réel de l’évolution de l’infrastructure ainsi que les coûts associés. Il est ainsi possible d’évaluer les plus gros investissements dans les ressources AWS, en temps réel, et en prévisionnel.
6. Conclusion sur les cloud data lakes
Si les data lakes cloud semblent être parfaits en regard de tous les avantages présentés, cela n’exclue pas que les fournisseurs de services présentent également des lacunes.
- Factures choquantes : Les clients ont déjà subi un choc de facturation dans le passé avec les fournisseurs cloud.Cependant, il existe des moyens d’éviter cela. AWS recommande par exemple d’activer la surveillance du compte (AWS Billing) : cela permettra d’envoyer une alerte avec une estimation de la facture mensuelle totale et de la facture mensuelle pour chaque service utilisé. Les notifications viendront par e-mail ou sms.
- Changement de fournisseur difficile en cas d’insatisfaction : Il est difficile de passer d’Amazon Web Services à un concurrent tel que Microsoft Azure ou vice versa. En effet, les deux sociétés utilisent des solutions de stockage et des API propriétaires. Les outils tiers utilisés pour le transfert de données peuvent ajouter à cette confusion. Les contrôles d’accès peuvent également être perdus lors de la conversion, les administrateurs devront donc s’assurer qu’il existe une cohérence dans les politiques d’accès et de protection sur les deux plates-formes. Une migration est extrêmement complexe : il se peut en réalité qu’une refonte complète du système soit nécessaire.
- Précaution pour l’utilisation des services : Les services proposés sont simples à l’utilisation et les utilisateurs peuvent avoir tendance à les surconsommer. Dans CloudWatch par exemple, il existe des triggers pour envoyer des alertes personnalisées et la configuration des services permet aussi de gérer l’autoscaling afin d’éteindre ou allumer des machines selon le besoin.
Sources :
Documentation officielle AWS https://docs.aws.amazon.com/ .
[1] : https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/concepts.html
[2] : https://docs.aws.amazon.com/toolkit-for-visual-studio/latest/user-guide/vpc-tkv.html
[3] : https://docs.aws.amazon.com/AmazonS3/latest/userguide/Welcome.html
[4] : https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Welcome.html
[5] : https://docs.aws.amazon.com/athena/latest/ug/what-is.html
[6] : https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Introduction.html
[7] : https://docs.aws.amazon.com/redshift/latest/gsg/getting-started.html
[8] : https://docs.aws.amazon.com/lambda/latest/dg/welcome.html
[9] : https://docs.aws.amazon.com/glue/latest/dg/what-is-glue.html
[10] : https://docs.aws.amazon.com/IAM/latest/UserGuide/introduction.html
[11] : https://docs.aws.amazon.com/awsaccountbilling/latest/aboutv2/billing-what-is.html

Par Ramzi Soltani
Ingénieur Data chez DataValue Consulting
La rédaction vous conseille
> Data warehouse, data lake, data hub : quelles différences ?
> Quels coûts directs et indirects pour votre migration Big Data ?
