1. IA et données personnelles : un débat sensible
L’Intelligence Artificielle (IA) dans sa définition strictement informatique fait référence à toute intelligence de type humain présentée par un ordinateur, un robot ou une autre machine. L’usage courant étend cette définition à la capacité d’un ordinateur ou d’une machine à imiter les capacités de l’esprit humain – apprendre des exemples et de l’expérience, reconnaître des objets, comprendre et répondre au langage, prendre des décisions – et la combinaison de ces capacités et d’autres pour exécuter des fonctions qu’un être humain pourrait accomplir, telles que saluer un client de l’hôtel ou conduire une voiture.

Les définitions d’une donnée privée, quant à elles, varient en fonction des lois applicables dans chaque situation, mais on peut la décrire de manière générale comme une information concernant une personne ou entité dont on peut raisonnablement s’attendre à ce qu’elle soit protégée de la vue du public. Le Règlement Général sur la Protection des Données (RGPD) de l’Union européenne par exemple définit : « données à caractère personnel, toute information relative à une personne physique identifiée ou identifiable (personne concernée)… directement ou indirectement »[1].
Un tour d’horizon des applications commerciales ou des recherches académiques en IA, montre qu’à mesure que ces modèles et algorithmes continuent de repousser les limites de l’état de l’art, leur appétit à consommer toute donnée disponible grandit de manière à empiéter sur les intérêts de la vie privée.
Le débat sur l’IA et l’utilisation des données sensibles fait souvent ressortir les limites et les défaillances de ces applications dites intelligentes. Les biais implicites, les collectes massives, et l’évolution rapide des technologies utilisées rendent les législations sur la protection de la vie privée assez compliquées et souvent à la traîne.
Cet article évoquera en premier lieu les enjeux d’un nouveau paradigme de protection de la vie privée. Nous nous intéresserons ensuite aux outils disponibles permettant de mettre en œuvre des systèmes d’IA performants tout en respectant les règles imposées par le règlement général sur la protection des données.
2. Les 4 piliers pour protéger les données personnelles dans les systèmes d’IA
Assurer la protection de la vie privée dans les systèmes d’IA et réglementer l’utilisation des données des consommateurs nécessitent donc un changement de paradigme. Cette nouvelle vision aborde la confidentialité dans le contexte de l’IA et les risques associés de manière plus holistique, avec des mesures conçues pour réglementer le traitement des données personnelles et identifier les cas de transgression.
Un certain nombre d’organisations, d’entreprises ainsi que plusieurs législateurs proposent différentes variations, mais elles s’articulent toutes autour de 4 piliers :
Explicabilité :
Comprendre comment les données ont été utilisées pour parvenir à une décision particulière et quelles sont les caractéristiques ayant joué un rôle important dans la conclusion n’est pas une mince affaire. Cela requière :
- (1) l’identification des décisions prises par l’IA
- (2) la décortication des décisions spécifiques
- (3) établir un moyen par lequel un individu peut chercher une explication.
La rétro-ingénierie des algorithmes d’apprentissage machine (Machines Learning) peut être difficile, voire impossible ; une difficulté qui augmente encore plus dans le cas des algorithmes d’apprentissage profond (Deep Learning).
La RGPD exige que, pour toute décision automatisée ayant des « effets juridiques ou des effets similaires significatifs » (le crédit, la couverture d’assurance, …) la personne concernée puisse recourir à un être humain capable de revoir la décision et d’expliquer sa logique [2]. L’incorporation d’un élément humain dans la boucle de prise décision ajoute une étape supplémentaire dans le processus de développement en plus d’une charge réglementaire importante.
Transparence :
Avoir une réponse claire à la question « Que fait l’entreprise de vos données ? » facilite grandement la responsabilisation de l’entreprise et dissipe les préoccupations des utilisateurs et/ou partenaires. La « politique de confidentialité » est un exemple concret. Ces documents traditionnellement longs et inutiles pour la plupart des consommateurs peuvent être remplacés par des déclarations :
- qui fournissent une description complète de la nature et de la manière dont les données sont collectées, utilisées et protégées,
- qui identifient les cas d’utilisation importants des données personnelles par l’IA et les divers algorithmes de prise de décisions implémentés dans un produit.
Évaluation des risques :
C’est une autre exigence de la RGPD pour les nouvelles technologies ou pour les utilisations à haut risque des données. Dans ce contexte, il s’agit d’évaluer et atténuer les risques de confidentialité à l’avance, notamment les biais potentiels dans la conception d’un système IA et les données fournies à ce système, ainsi que l’impact potentiel sur les utilisateurs. Ainsi le réseau social Twitter a crée la polémique en septembre dernier car il a été démontré par des utilisateurs que son algorithme de recadrage de photo était “racialement” biaisé[3]..
Audits :
Qu’il s’agisse d’audits internes (auto-audits) ou externes (par des organismes tiers), les audits restent nécessaires pour le suivi et le respect des exigences. Comme les audits ont une nature rétrospective, une bonne stratégie est de combiner leurs résultats pour des décisions de l’IA avec les évaluations des risques qui sont proactives. Cela peut éclairer mieux la position de l’entreprise sur le plan de l’IA et la confidentialité bien que, comme l’explicabilité, l’audit des algorithmes d’apprentissage machine soit difficile et toujours en développement.
3. IA et confidentialité : les tendances techniques majeures
Satisfaire toutes les contraintes précédemment listées tout en préservant la performance du système AI peut sembler difficile, voire impossible mais il existe plusieurs solutions à explorer, en particulier l’Apprentissage fédéré et la Confidentialité différentielle.
L’Apprentissage Fédéré (Federated Learning) est une approche novatrice pour entraîner des modèles d’apprentissage machine de manière décentralisée. La dissociation entre le processus d’entraînement et le besoin de stocker les données en interne permet aux entreprises de débloquer plus de capacités en diminuant les coups et risques possibles.
Cette méthode d’apprentissage va au-delà de l’utilisation des modèles locaux qui font des prédictions sur les périphériques de l’utilisateur, vers une vraie collaboration entre les appareils membres de cette architecture :
- Le même modèle d’apprentissage machine est tout d’abord déployé sur tous les appareils,
- Ces derniers complètent ensuite la phase d’entrainement avec leurs données locales et mettent à jour les poids et hyper-paramètres du modèle localement,
- Puis ils envoient séparément ces mises à jour au Cloud ou au serveur central à l’aide d’une communication cryptée. Ces mises à jour sont ensuite regroupées et moyennées pour obtenir les poids et hyper-paramètres moyens du modèle partagé. Plus important encore, toutes les données d’entraînement restent sur l’appareil de l’utilisateur et aucune mise à jour individuelle n’est stockée de manière identifiable dans le Cloud.
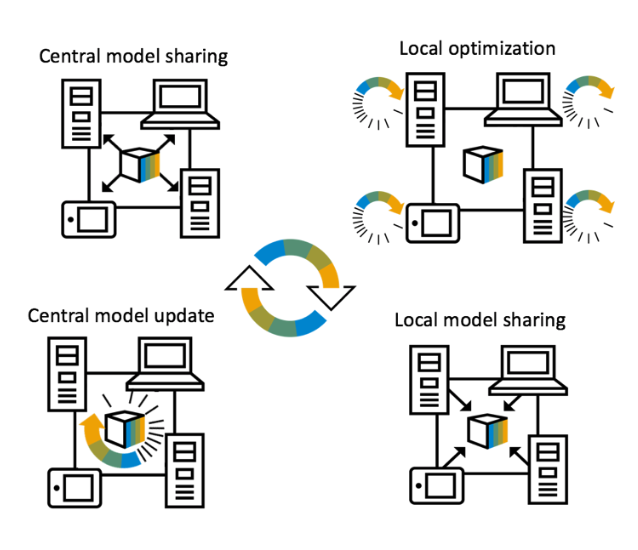
Figure 1 : Communication dans une architecture d’apprentissage fédéré [4]
> À LIRE AUSSI : Data Science, Intelligence Artificielle, Machine Learning et Deep Learning… Un éclairage sur les définitions, points de convergence et différences
Un exemple phare de ce type d’application est la fonctionnalité « Gboard » développée pour les Smartphones Android : Lorsque Gboard affiche une suggestion, votre téléphone stocke localement des informations sur le contexte actuel et si vous avez cliqué sur la suggestion (est ce que la suggestion était utile ou non ?), le modèle d’apprentissage fédéré s’entraîne localement sur cet historique et les millions d’appareils Android partage leur résultats (nouveaux poids et paramètres) pour avoir des améliorations à la prochaine itération du modèle IA de Gboard.
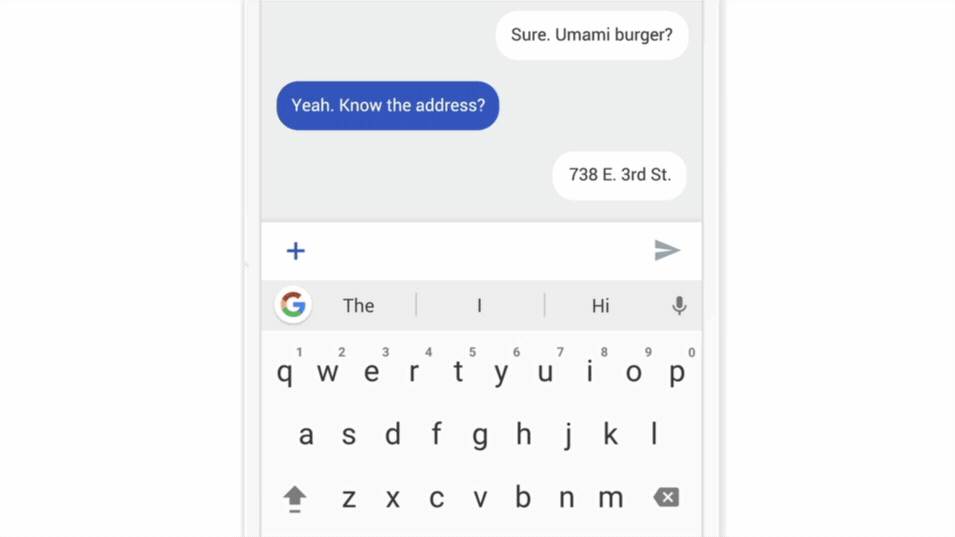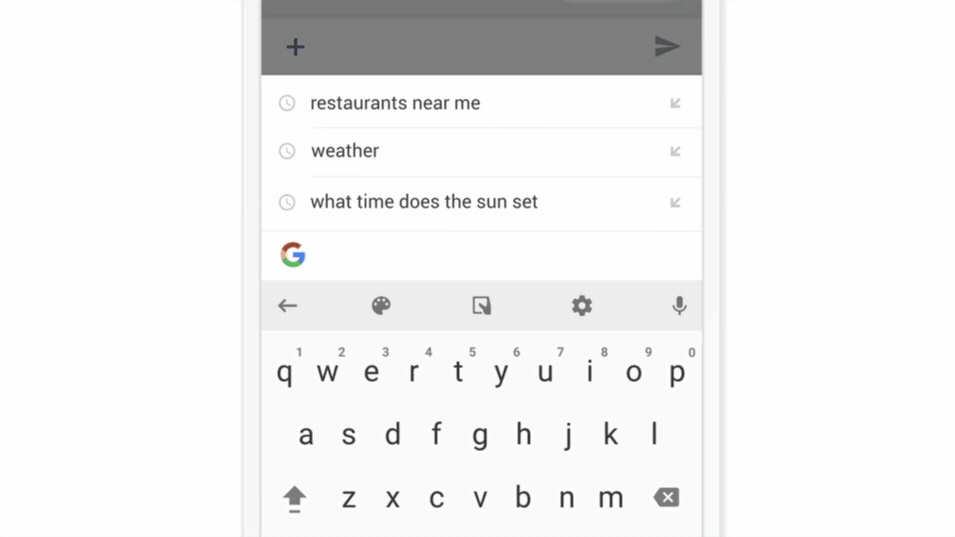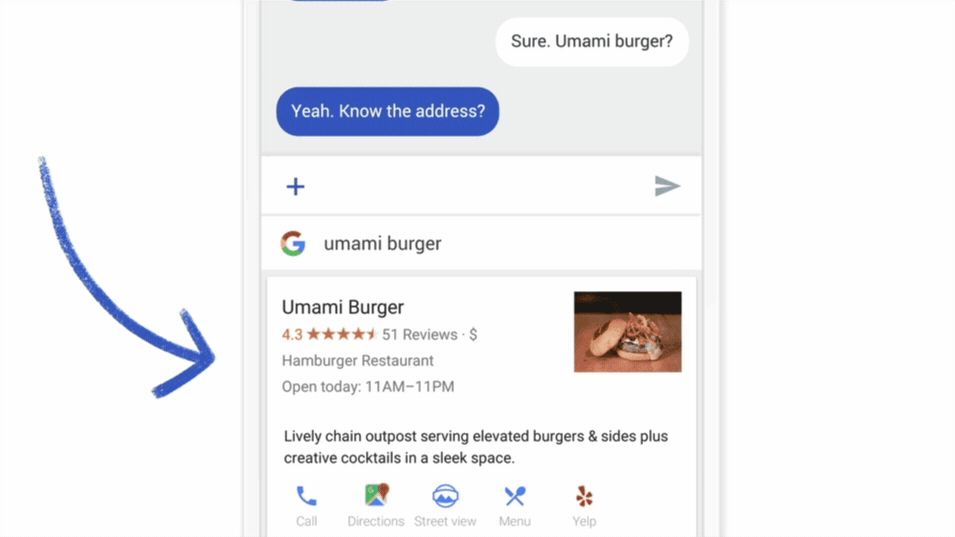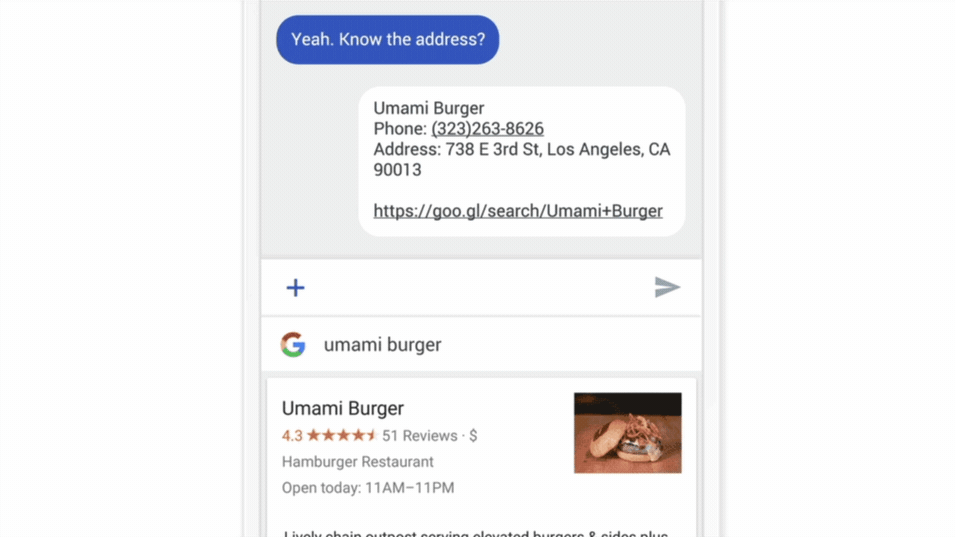
Figure 2 : Fonctionnement du service Google Keyboard [5]
La Confidentialité Différentielle (Differential Privacy) transforme les données de leur état brut vers un format qui permet aux organisations d’apprendre de la majorité de ces données tout en s’assurant simultanément que les résultats ne permettront pas de distinguer ou de ré-identifier les données d’un individu.
Depuis le début des années 2000, des recherches ont démontré que 87% de la population américaine est identifiée de manière unique par la combinaison {date de naissance, sexe, code postal}[6]. En 2007 une base de données anonyme publiée par Netflix a été rétro-conçue par des chercheurs qui ont démasqué les préférences et avis de 500 000 utilisateurs de la plateforme [7].
De grands acteurs tels que Microsoft, Google, ou encore Apple, se sont tournés vers la confidentialité différentielle pour aider à garantir la confidentialité des données sensibles. Cette attention de la part de grandes entreprises technologiques a contribué à faire sortir la confidentialité différentielle des laboratoires de recherche et à l’intégrer dans la conception d’applications et le développement de produits.
La confidentialité différentielle est maintenant une technique aussi bien adoptée par les PME (petites et moyennes entreprises) que par les startups de logiciels, car elles y trouvent une grande valeur ajoutée.

Figure 3 : Exemple de jeu de données anonymisées
Le mécanisme de la confidentialité différentielle ajoute essentiellement du bruit (typiquement Gaussien ou Laplacien) aux données brutes pour atteindre un niveau quantifiable de confidentialité. En connaissant ce niveau, on peut estimer la quantité d’informations maximale qui pourra être divulguée dans notre jeu de données.
Il existe deux méthodes principales :
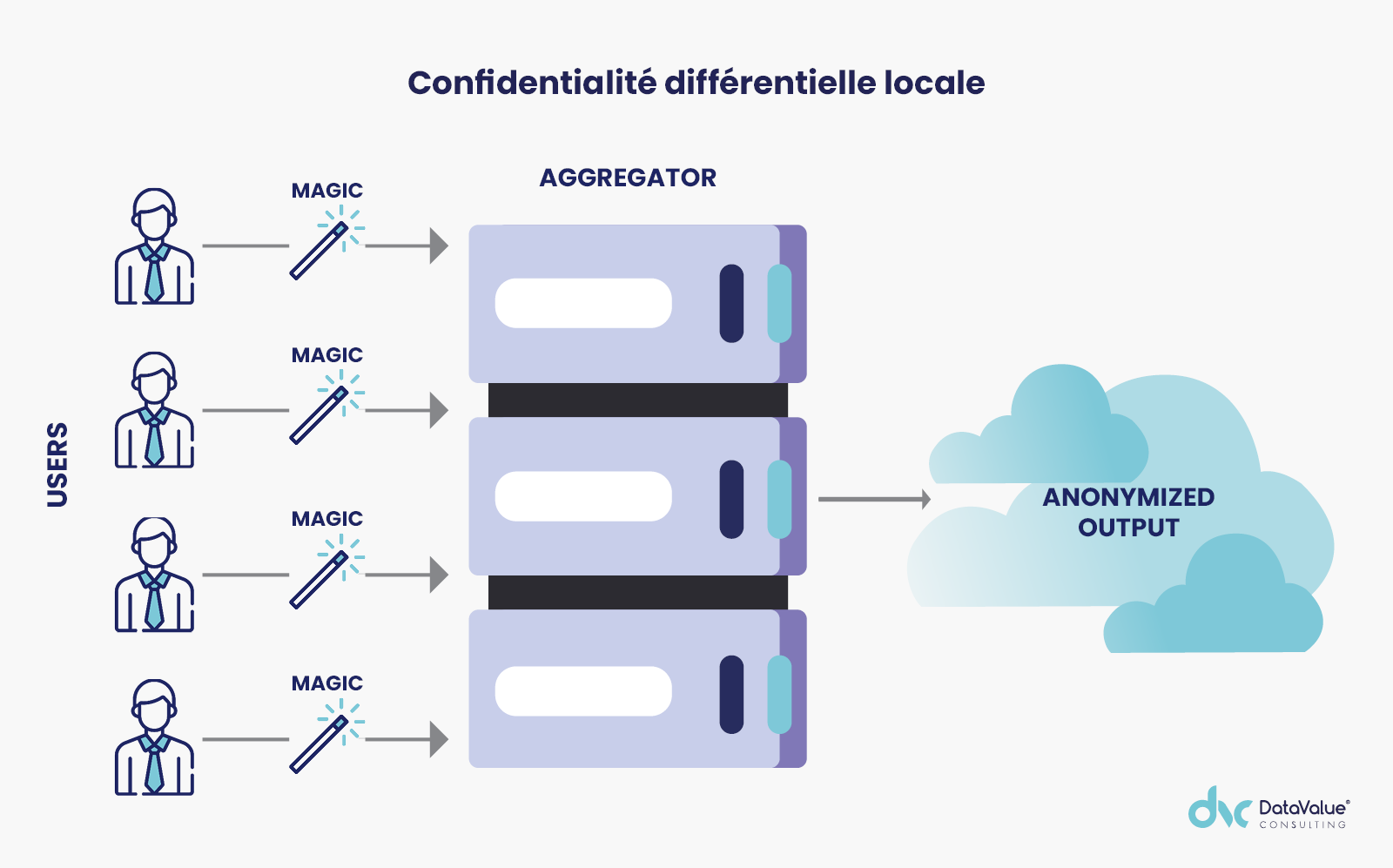
Confidentialité différentielle locale = le bruit est ajouté à chaque point de données individuel dans l’ensemble de données (soit par un des collaborateurs de l’entreprise une fois les données obtenues, soit par les individus eux-mêmes avant de mettre leurs données à la disposition de l’entreprise).
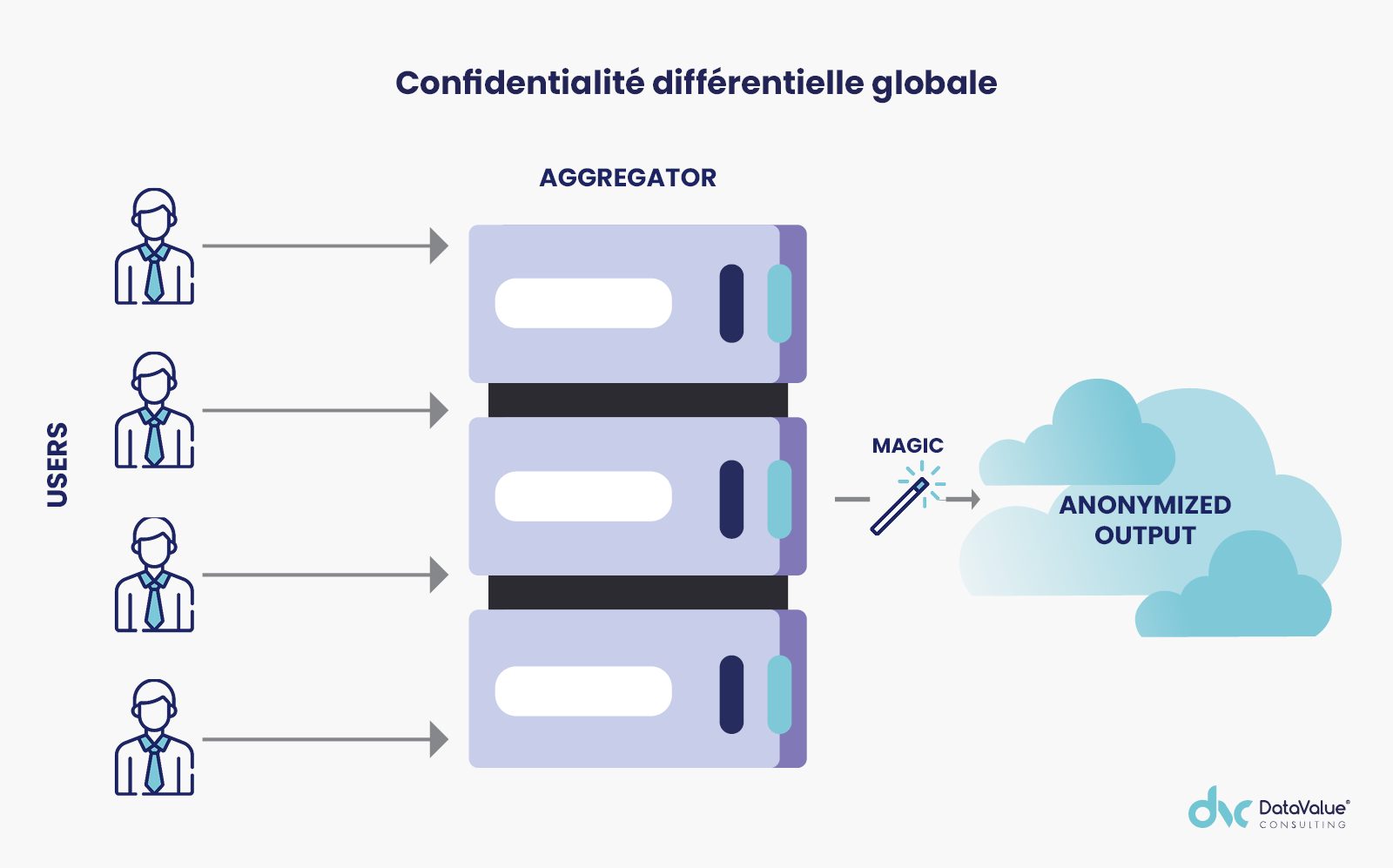
Confidentialité différentielle globale = le bruit nécessaire pour protéger la vie privée de l’individu est ajouté à la sortie de la requête faite sur les données brutes.
En règle générale, la confidentialité différentielle globale peut conduire à des résultats plus précis par rapport à la confidentialité différentielle locale, tout en conservant le même niveau de confidentialité. D’autre part, lors de l’utilisation de la confidentialité différentielle globale, les personnes qui font don de leurs données doivent avoir confiance au fait que l’entité destinataire ajoutera le bruit nécessaire pour préserver leur confidentialité.
Conclusion
L’alliance entre la performance de l’IA et le respect de la confidentialité des données est une quête difficile mais pleine d’opportunités et de promesses. Il est clair qu’aucune mesure appliquée de façon isolée ne peut être totalement efficace pour éviter les dérives. Ainsi, là où les décisions des algorithmes intelligents sont conséquentes, il est logique de combiner des mesures à plusieurs niveaux pour les faire travailler ensemble.
Sources :
[1] Article 4, paragraphe 1 de la RGPD : https://gdpr-info.eu/art-4-gdpr/
[2] Raison 71 de la RGPD : https://gdpr-info.eu/recitals/no-71/
[3]https://memeburn.com/2020/09/twitter-investigating-cropping-algorithm-after-users-flag-racial-bias/
[4] Privacy-preserving Collaborative Machine Learning; by Robin Geyer, Moin Nabi and Tassilo Klein : https://medium.com/sap-machine-learning-research/privacy-preserving-collaborative-machine-learning-35236870cd43
[5] Federated Learning: Collaborative Machine Learning without Centralized Training Data, Google AI Blog: https://ai.googleblog.com/2017/04/federated-learning-collaborative.html
[6] Policy and Law: Identifiability of de-identified data, by Latanya Sweeney, Ph.D. http://www.latanyasweeney.org/work/identifiability.html
[7] How To Break Anonymity of the Netflix Prize Dataset; by Arvind Narayanan, Vitaly Shmatikov: https://arxiv.org/abs/cs/0610105
La rédaction vous conseille
> Découverte du Machine Learning avec Python et le Framework Ray
